 на главную сниппетов
на главную сниппетов Чего мне всегда не хватало, так это аналога JSFiddle для SQLite. Онлайн-песочницы, в которой можно быстро проверить SQL-запрос и поделиться с другими.
Вот чего хотелось:
Возможность загрузить готовую базу, а не писать SQL для создания таблиц.
Подключать как локальные базы, так и удаленные (по url).
Сохранять базу и запросы в облаке.
Бесплатно и без регистрации.
Свежайшая версия SQLite.
Минимализм.
В итоге сделал такую песочницу сам.
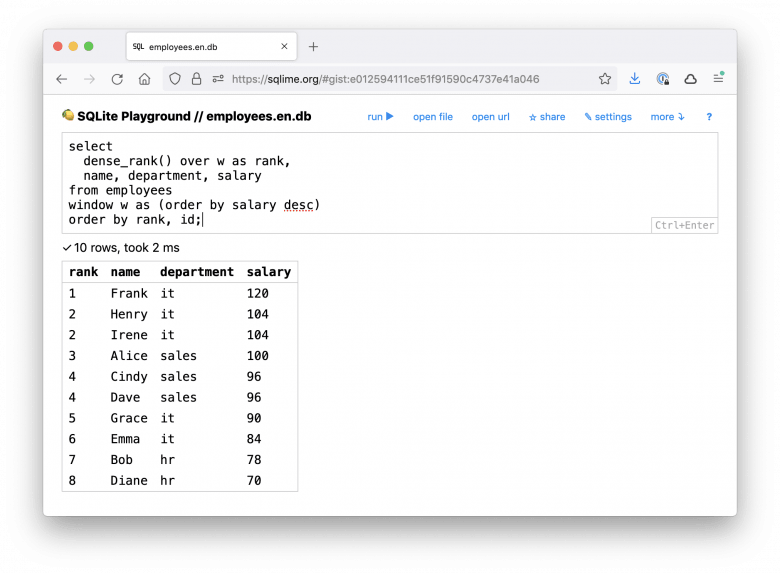
Сначала покажу результат, потом расскажу, как все устроено:
Теперь подробности.
Абсолютно во всех браузерах — что мобильных, что десктопных — уже встроена отличная СУБД, которая реализует стандарт SQL-92 (и большой кусок более поздних стандартов) — SQLite. Логично было бы дать к ней доступ через API браузера.
В конце нулевых многие браузерные вендоры так думали. Тогда появился стандарт Web SQL, который поддержали Apple (Safari), Google (Chrome) и Opera (еще популярная тогда). А Mozilla (Firefox) — нет. В результате в 2010 Web SQL убили, и дальше хранение данных в браузере пошло по NoSQL-пути (Indexed Database, Cache API).
В 2019 году Офир Ложкин скомпилировал исходники SQLite в WebAssembly («родной» бинарный формат для браузера) — так появился проект sql.js. Это полноценная СУБД SQLite, которая работает в браузере (благо, она небольшая — бинарник занимает 300+ Кб).
sql.js — идеальный движок для онлайн-песочницы. Его я и взял.
Получаем файл от пользователя через input[type=file], считываем через FileReader, преобразуем в 8-битный массив и загружаем в SQLite:
const file = event.target.files[0];
const reader = new FileReader();
reader.onload = function () {
const arr = new Uint8Array(reader.result);
return new SQL.Database(arr);
};
reader.readAsArrayBuffer(file);Загружаем файл с помощью fetch(), начитываем ответ в ArrayBuffer, а дальше как с обычным файлом:
const resp = await fetch(url);
const buffer = await response.arrayBuffer();
const arr = new Uint8Array(buffer);
return new SQL.Database(arr);Одинаково хорошо работает с локальными и удаленными URL. Удобно загружать базы, которые хостятся на гитхабе — достаточно использовать домен raw.githubusercontent.com вместо github.com. Например:
https://github.com/nalgeon/sqliter/blob/main/employees.db
→ https://raw.githubusercontent.com/nalgeon/sqliter/main/employees.dbПожалуй, самая простая часть — sql.js предоставляет удобное API для запросов:
// выполнить один или несколько запросов
// и вернуть результат последнего из них
const result = db.exec(sql);
if (!result.length) {
return null;
}
return result[result.length - 1];Бинарный контент базы получить несложно — sql.js предоставляет отдельный метод:
const buffer = db.export();
const blob = new Blob([buffer]);
const link = document.createElement("a");
link.href = window.URL.createObjectURL(blob);
// ...
link.click();Но мне хотелось сохранять не бинарник, а полный SQL, который создает схему и заполняет таблицы данными. Так результат можно посмотреть глазами и загрузить в PostgreSQL или другую СУБД.
Для экспорта базы в SQL я воспользовался алгоритмом питонячей утилиты sqlite-dump. Код довольно объемный, поэтому не буду приводить здесь (если интересно, подробности в dumper.js). Вкратце:
Получаем список таблиц из системной таблицы sqlite_schema, формируем запросы create table...
Для каждой таблицы получаем список столбцов из виртуальной таблицы table_info(name).
Выбираем данные из каждой таблицы и формируем запросы insert into...
Получается вполне читаемый скрипт:
CREATE TABLE IF NOT EXISTS employees (
id integer primary key,
name text,
city text,
department text,
salary integer
);
INSERT INTO "employees" VALUES(11,'Дарья','Самара','hr',70);
INSERT INTO "employees" VALUES(12,'Борис','Самара','hr',78);
INSERT INTO "employees" VALUES(21,'Елена','Самара','it',84);
...Базу и запросы нужно где-то хранить, чтобы можно было поделиться ссылкой на заполненную песочницу. Меньше всего хотелось пилить бекенд с авторизацией и хранилищем — пришлось бы сделать сервис платным, да и для людей лишняя головная боль с регистрацией.
К счастью, есть GitHub Gist API, который идеально подходит по всем критериям:
многие разработчики уже зарегистрированы на гитхабе;
разрешен CORS (можно делать запросы с других доменов);
приятный интерфейс пользователя;
бесплатный и надежный.
Интеграция через обычный fetch(): GET на выборку гиста, POST на сохранение.
// формируем SQL-скрипт из базы
const data = export(db);
// сохраняем в виде гиста
fetch("https://api.github.com/gists", {
method: "post",
headers: {
Accept: "application/json",
"Content-Type": "application/json",
Authorization: `Token ${token}`
},
body: JSON.stringify(data),
});От пользователя требуется только указать гитхабовский API-токен. Удобно, что токену можно дать разрешение исключительно на работу с гистами — сделать что-то плохое в репозиториях по такому токену заведомо не получится.
Современные фронтенд-проекты переполнены тулингом и инфраструктурными штуками, а мне это совсем не интересно (я не js-разработчик). Поэтому сознательно не стал использовать UI-фреймворки и сделал все на ванильном html + css + js. Кажется, для небольшого проекта это вполне допустимо.
Код при этом получился достаточно модульным, благодаря нативным js-модулям и веб-компонентам — их поддерживают все современные браузеры. Наверно, настоящий фронтендер поморщится, но мне норм.
Хостится песочница на GitHub Pages, а деплой сводится к обычному git push. Поскольку этапа сборки нет, не пришлось даже настраивать GitHub Actions.
Буду рад, если SQLite-песочница вам пригодится. Или, возможно, кому-то окажется полезен сам подход к созданию бессерверных проектов на JS + GitHub API. За конструктивную критику тоже буду благодарен, конечно ツ
на главную сниппетов

