 на главную сниппетов
на главную сниппетовНачнем с простого перечисления наиболее используемых.
Нужно обязательно сделать ремарку, что некоторые крупные производители, имеют в своем арсенале несколько типов СУБД, как в виде отдельных продуктов, так и в виде внутренней реализации. Например, у Oracle на самом деле чего только нет, начиная с классической реляционной СУБД, продолжая с отдельным продуктом Oracle NoSQL Database, который может использоваться и как документная, и как колоночная, и как ключ-значение. Отдельное решение от того же Oracle, Autonomous Data Warehouse – это уже специализированное решение для хранилищ данных. Еще один отдельный продукт от Oracle – Oracle Graph Server для работы с графами, и еще много другого. Этому можно посвятить отдельную серию статей.
Начнем по порядку, классические, реляционные СУБД чаще всего используются для построения решений OLTP (Online Transaction Processing). В таких решениях СУБД работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом от системы требуется минимальное время отклика, а так же возможность, при определенных условиях, отменить любые изменения выполняемых в рамках транзакции. Если вы строите систему, в рамках которой требуется хранить значительное количество сущностей (таблиц), с различными типами связей между ними (один-к-одному, один-к-многим, многие-ко-многим), то это скорее всего про реляционные СУБД.
Наиболее известные СУБД такого типа – Oracle, Microsoft SQL, PostgreSQL, MySQL.
Один из основных признаков, который говорит о том что нужно выбирать реляционную СУБД – это высокая нормализация данных. Дополнительными признаками будет необходимость обработки большого кол-ва коротких транзакций, с большей долей операций на вставку
Если предполагается хранить не структурируемые данные, или наоборот очень простые структуры типа ключ-значение, то лучше посмотреть в сторону документных СУБД и специализированных СУБД типа ключ-значение соответственно.
Так же один из признаков, что имеет смысл подумать не о реляционных СУБД, это такой факт как необходимость часто обновлять значения в одних и тех же строках. Обычно это обходится “дорого” в реляционных СУБД, и нужно применять “продвинутую магию” что бы делать это корректно.
Конечно, тут есть много «но», или «а если очень хочется», и других ситуаций, когда данные рекомендации можно игнорировать. Это нормально, особенно когда за дело берется эксперт, который знает как это сделать.
Наверное один из самых простых типов СУБД. В упрощенном виде, это некая таблица с уникальным ключом и собственно связанным с ним значением, в котором может быть что угодно. Чаще всего такие СУБД используют для кэширования, т.к. они очень быстро работают, а это и не сложно, когда есть уникальный ключ, и запрос возвращает только одно значение. У некоторых представителей данных СУБД есть возможность работать полностью в памяти, а так же есть возможность задавать срок жизни записи, после истечения которого, записи будут автоматически удаляться.
Наиболее известные СУБД такого типа – Redis и Memcached.
Если СУБД будет использоваться для кэширования данных или для брокеров сообщений, то это очень подходящий тип. Так же, такая СУБД хорошо подходит для баз где нужно хранить достаточно простые структуры, и иметь к ним очень быстрый доступ.
Если вы предполагаете хранить в базе данных много сущностей (таблиц), а у сущностей будут сложные структуры с разными типами данных. Так же, если вы предполагаете делать из этой таблицы сложные запросы которые возвращают множества строк.
Документные или документно-ориентированные СУБД – это одна из наиболее популярных разновидностей NoSQL СУБД, где основной единицей логической модели данных является документ – структурированный текст, с определенным синтаксисом.
Иногда встречаются мнения что модель данных в документных БД похожа на модель данных в объектно-ориентированных базах данных. В этом есть доля правды, единственная реальная разница между ними заключается в том, что базы данных документов только сохраняют состояние, но не поведение.
Так же, само название “документо-ориентированная” подчас вводит в заблуждение, и мне встречались коллеги, которые считали, что это база для систем документооборота. Нет, это не так.
Интересно, что документные СУБД развиваются достаточно активно, и сейчас некоторые из них, в том числе, поддерживают проверку схемы.
Известными представителями таких СУБД являются CouchDB, MongoDB, Amazon DocumentDB.
Если нужно хранить объекты в одной сущности, но с разной структурой. Если нужно хранит структуры, включая объекты, списки и словари, особенно в формате близкому к JSON.
На самом деле область применения документных СУБД очень широкая. Их можно использовать как компактную базу данных для отдельно взятого микро-сервиса, так и для вполне масштабных решений, в качестве хранилища состояний чего-либо.
Не самое лучшее решение для реализации транзакционная модели, и точно не лучший вариант для формирования отчетности.
Графовые СУБД – специфичный тип, предназначены для работы с графами, с их узлами, свойствами, и произвольными отношениями между узлами.
Очень простой пример, это организация связей в различного типа социальных сетях, где нужно хранить связи между пользователями (узлами) по разным критериям (родственные связи, коллеги, общие интересы).
Известные представители этого типа субд – Neo4j, Amazon Neptune, InfiniteGraph, InfoGrid.
Точно стоит обратить внимание на графовые СУБД, если строите какое-то подобие социальной сети, или реализуете систему оценок и рекомендаций. Ну и во всех случаях когда вы хорошо понимаете что такое графы, и для чего это нужно.
Практически во всех остальных случаях, кроме указанных выше, лучше воздержаться от использования графовых СУБД.
Колоночные СУБД очень похожи на реляционные. Они так же состоят из строк, которые имеют атрибуты, а строки группируются в таблицах. Различия в логических моделях несущественные, а вот на уровне физического хранения данных различия значительные.
В реляционных СУБД данные хранятся “построчно”, это означает что для считывания значения определенной колонки, придется прочитать практически всю строку, как минимум от первой до нужной колонки. В колоночной СУБД данные хранятся “поколоночно”, т.е. колонка – это как отдельная таблица. Соответственно чтение будет происходить из конкретного столбца сразу. На практике это реально работает очень быстро (проверено мной на нескольких реализованных хранилищах данных).
Основные преимущества колоночных СУБД – эффективное выполнения сложных аналитических запросов на больших объемах, и легкое, практически мгновенное, изменение структуры таблиц с данными, плюс существенная компрессия и сжатие, которое позволяет значительно экономить место.
Яркие представители колоночных СУБД – Sybase IQ (ныне SAP IQ), Vertica, ClickHouse, Google BigTable, InfoBright, Cassandra.
Один из весомых аргументов за использование именно колоночной СУБД – это если вы хотите построить хранилище данных, и планируете делать выборки со сложными аналитическими вычислениями. Косвенный признак, который так же может сигнализировать о том, что имеет смысл, хотя бы посмотреть в сторону колоночных СУБД – это если количество строк, из которых делаются выборки, превышает сотни миллионов.
Учитывая специфику колоночных СУБД, будет не эффективно ее использовать, если выборки достаточно простые, параметры выборки статичны, и если преобладают выборки по ключевым значениям. Так же, если количество строк в таблице, из которой делается выборка, меньше сотен миллионов строк, то скорее всего не будет большого преимущества, по сравнению с реляционной СУБД.
Нужно так же иметь ввиду, что в колоночных СУБД могут быть и другие ограничения. Например, может отсутствовать поддержка транзакций, а язык запросов может отличаться от классического SQL, и прочее.
Важное замечание – не пытайтесь сразу все задачи решить в рамках одной СУБД. Это более чем нормально иметь несколько разных типов СУБД. Так же, не пытайтесь сразу определиться с производителем СУБД, или связать свою жизнь с одним конкретным брендом.
При выборе типа СУБД следует, прежде всего, исходить из типа решаемых задач, типов обрабатываемых данных, перспектив роста и масштабирования.
Обращайте так же внимание на популярность и наличие широкого круга разработчиков и средств разработки – это даст вам возможность, при необходимости, найти ответ на возникший вопрос быстро.
После публикации статьи “Какую СУБД выбрать и почему? (Статья 1)” ко мне поступили справедливые комментарии о том, что я не упомянул такие типы СУБД, как Time Series и Spatial. В этой статье я кратко опишу их и добавлю еще два типа — Search engines и Object-oriented (объектные).
Напомню, в предыдущей статье мы описали:
Реляционные
Ключ-значение
Документные
Графовые
Колоночные
В этой опишем:
Time Series
Spatial
Search engines
Object-oriented (объектные)
В заключении я традиционно добавлю сводную таблицу со всеми типами СУБД — теперь их девять. Если вас интересует только компактное обобщение (тип, когда выбирать, популярные СУБД этого типа), то можете просто пролистать в самый конец.
Такие СУБД оптимизированы для хранения данных временных меток или временных рядов. Данные временных рядов могут содержать измерения или события, которые отслеживаются, собираются или объединяются в течение определенного периода времени. Это могут быть данные, собранные с датчиков отслеживания движения, метрики JVM из приложений Java, рыночные торговые данные, сетевые данные, ответы API, время безотказной работы процессов и т.д.
Данные хранятся с отметками времени (это ключевое), которые индексируются и записываются таким образом, чтобы можно было запрашивать данные этих временных рядов намного быстрее, чем при использовании классической реляционной базы данных.
Наиболее известные СУБД такого типа: InfluxDB, Kdb+, Prometheus, TimescaleDB, QuestDB, AWS Timestream, OpenTSDB, GridDB.
Основная область применения таких СУБД — это системы мониторинга, сбора телеметрии и финансовые системы.
Желательно воздержаться от применения такой СУБД для задач, не связанных с временными рядами и временными метками.
Как следует из названия, такие СУБД оптимизированы под хранение и работу с объектами. Как и полагается в ООП, у таких объектов в СУБД также имеются свойства и методы. Так же в них реализованы инкапсуляция и полиморфизм. Основная цель использования объектных СУБД — избавить разработчиков, применяющих объектную модель программирования, от необходимости трансформировать объекты в таблицы, строки и их связи, и обратно.
Яркие представители этого типа СУБД: MongoDB Realm, InterSystems Caché, ObjectStore, Actian NoSQL DB, Objectivity/DB.
Честно говоря, я видел не так много успешных реализаций с использованием объектных СУБД. Тем не менее, объектные базы данных обычно рекомендованы для тех случаев, когда требуется высокопроизводительная обработка данных, имеющих сложную структуру, при этом разработка ведется с использованием языков объектно-ориентированного программирования.
Не выбирайте объектную СУБД, если вы планируете использовать классический язык SQL, если вы не используете ООП или если вы планируете в дальнейшем мигрировать с данной СУБД на другие. Если нет хорошего понимания ООП, в большинстве случаев лучше выбрать документо-ориентированные СУБД.
Такой тип СУБД используется для организации полнотекстового поиска. Причем поиск может производиться по различным данным — это например, данные из других БД, e-mail, RSS-feed, текст, JSON, XML, CSV, и даже по документам PDF и MS Office. У Search engine СУБД свои оптимизированные подходы к индексированию данных. В том числе используются так называемые инвертированные индексы, для того, чтобы предоставлять практически real-time поиск. В разных СУБД данного типа могут использоваться свои языки запросов, отличающихся друг от друга.
Известные СУБД данного типа: Apache Solr, Elasticsearch, Splunk.
Подходят для организации быстрого полнотекстового поиска по различным источникам данных, как по структурированным, так и по слабо структурированным. Яркий пример — системы сбора логов и поиска по ним.
Если поиск производится по ограниченному количеству полей структурированных данных.
Этот тип СУБД оптимизирован и предназначен для работы с объектами определенными в геометрическом пространстве. Это могут быть простые объекты (точки, линии, многоугольники) или сложные (3D-объекты, топологические покрытия, линейные сети). В таких СУБД реализован набор специальных функций, позволяющих проводить с объектами операции создания, трансформации, измерения (расстояния, площади, объема), вычисления (пересечений \ соприкосновений) и выборки по определенным критериям. В таких СУБД существуют специальные индексы, оптимизирующие работу с объектами, и специальный стандартизированный SQL/MM язык.
Известные представители этого типа СУБД: Oracle Spatial, Microsoft SQL, PostGIS, SpatialLite.
Если строите GIS-решения. Если планируете не просто хранить, но и работать с геометрическими объектами на уровне СУБД.
Если планируете просто хранить геометрические объекты в виде координат.
Мы пополнили наш перечень типов СУБД еще четырьмя: Time series, Object-oriented, Search engines и Spatial. Это все еще не полный перечень, и в одной из следующих статей мы продолжим. Отдельно рассмотрим несколько крупных вендоров, которые предлагают сразу множество типов СУБД.
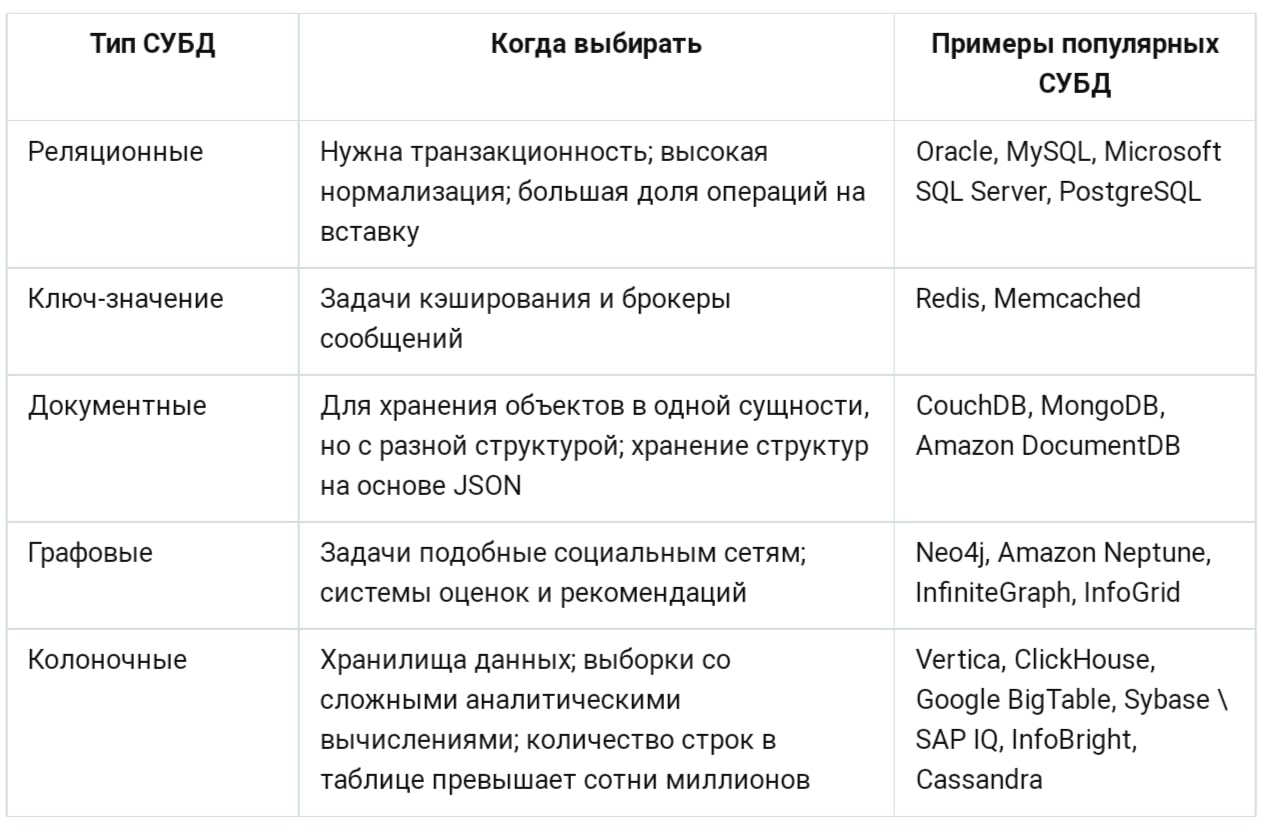
№ |
Тип СУБД |
Когда выбирать |
Популярные СУБД данного типа |
1 |
Реляционные |
Нужна транзакционность; высокая нормализация; большая доля операций на вставку |
Oracle, MySQL, Microsoft SQL Server, PostgreSQL, IBM DB2, SQLite |
2 |
Ключ-значение |
Задачи кэширования и брокеры сообщений |
|
3 |
Документные |
Для хранения объектов в одной сущности, но с разной структурой; хранение структур на основе JSON |
|
4 |
Графовые |
Задачи подобные социальным сетям; системы оценок и рекомендаций |
|
5 |
Колоночные |
Хранилища данных; выборки со сложными аналитическими вычислениями; количество строк в таблице превышает сотни миллионов |
Vertica, ClickHouse, Google BigQuery, Sybase \ SAP IQ, InfoBright |
6 |
Time series |
Системы мониторинга, сбора телеметрии, и финансовые системы, с привязкой к временным меткам или временным рядам |
InfluxDB, Kdb+, Prometheus, TimescaleDB, QuestDB, AWS Timestream, OpenTSDB, GridDB |
7 |
Объектные |
Высокопроизводительная обработка данных, имеющих сложную структуру, с использованием языков объектно ориентированного программирования |
MongoDB Realm, InterSystems Caché, ObjectStore, Actian NoSQL DB, Objectivity/DB |
8 |
Search engine |
Системы полнотекстового поиска |
|
9 |
Spatial |
GIS-решения, работа с геометрическими объектами |
на главную сниппетов

