Управление — трудоёмкая работа, которая усложняется при отсутствии подходящего инструмента. Легко упустить из виду постоянно меняющиеся компоненты и сложно быть в курсе событий: что-то обязательно проходит незамеченным.
Grafana позволяет собрать на одном экране разную информацию:
- результаты тестов в режиме реального времени,
- срезы по окружениям, браузерам и чему угодно ещё,
- скорость выполнения тестов,
- покрытие тестами страниц и действий на них,
- результаты релизов.
Этот список можно продолжать и вводить новые метрики для задач тестирования. Расположение метрик на одном экране позволяет получать прозрачные отчёты о тестировании, которые понятны и инженерам, и руководителям. Главное в этом деле — научиться измерять и правильно подсвечивать проблемы. Тогда управлять тестированием станет проще.
На примерах наших тестов покажу, как Grafana помогает в анализе результатов автотестирования, чтобы точнее понимать, что происходит.

Наш контекст
Про сайт Ozon.ru
Сайт написан на TypeScript (Vue) и представляет собой монолитный репозиторий. Каждую страницу сайта делает отдельная команда (в нашей терминологии — «вертикаль»). Она отвечает за фронтенд, бэкенд, дизайн, аналитику и остальное необходимое для функционирования страницы.
Выпускаем до десяти релизов сайта в день, которые нужно быстро тестировать. В этом нам помогает
WebdriverIO, а для запуска тестов используем
Moon.
Автоматические тесты для сайта
Автотесты делим на две группы:
- Критичные сценарии. Это такие тесты от каждой вертикали, которые позволяют проверять работоспособность важной функциональности сайта Ozon.
- Вертикальные сценарии. Это тесты, которые не вошли в список критичных, но более тщательно проверяют функциональность, за которую ответственна каждая вертикаль.
Каждая вертикаль предоставляет тесты для критичного набора — всего около 300: тесты сайта, мобильной версии, аналитики. А общий набор вертикальных тестов содержит около 1500 сценариев.
Во время релиза мы прогоняем все критичные тесты, а также тесты той вертикали, чья страница релизится. Кроме того, мы регулярно прогоняем все тесты по расписанию, чтобы дополнительно отслеживать работу продакшен- и стейджинг-сред.
Кстати, подробнее про это я уже рассказывал в статье «
Автоматическое тестирование аналитики в браузере».
Тестирование в продакшене
Здесь важно сделать отступление. На самом деле, тестирование в продакшене — это тема для отдельной статьи. Скажу, что мы не стесняемся использовать продакшен-среду для тестирования, — считаем, что чем ближе к пользователю, тем вернее, точнее, честнее проверки.
Мы используем blue-green деплой для проверки релизов: сервис выкладывается в прод, тестируется, и только потом пускается трафик пользователей. Никаких лишних действий после тестирования не происходит: протестировали — сразу пускается трафик.
Мы мониторим тестами продакшен: делаем это не ради перестраховки или дублирования мониторинга, а потому что, кроме релизов, вносятся изменения в конфигурации, в админки и в шаблоны страниц.
Проблемы при тестировании
Итак, возвращаемся к проблеме, которую я упомянул во вступлении.
Нам нужно управлять тестированием и принимать решения о релизах, понимать, есть в данный момент какие-то проблемы или нет. Неизвестных здесь тьма. Приведу мой топ проблем:
- Разработчики пренебрегают изучением отчётов о тестировании. Мало кто заглядывает в Allure, а если заглядывают, то не вполне понимают локаторы и сами сценарии.
- Руководителям не хочется погружаться в детали — они хотят иметь картинку перед глазами.
- Тесты постоянно падают или моргают (flaky-тесты).
- Недостаточное покрытие. А как его оценить?
- Недостаточная скорость работы тестов.
Решение
Чтобы преодолеть эти трудности, нужно научиться измерять работу тестов. В этом помогает Grafana — инструмент, которым пользуются разработчики, девопсы, аналитики, продакт-менеджеры. Grafana отображает графики и результаты аналитики.
Как технически организовать сбор метрик
В Ozon уже создана инфраструктура для сбора всевозможных метрик: сейчас в эксплуатации больше 10 000 экземпляров сервисов, с которых мы каждую секунду собираем около миллиона уникальных метрик для бессрочного хранения. Тестировщики быстро втянулись и начали использовать эту инфраструктуру.
Всё, что нам нужно было сделать, — подобрать библиотеку для отправки метрик в
Prometheus. Делая запросы в Prometheus, показываем результаты тестирования в Grafana. На
официальном GitHub Prometheus можно подобрать библиотеку для любого языка.
После выполнения каждого теста добавляем хук, который отправляет метрики с его результатами:
afterTest: (t: Test, _, r: TestResult): void => {
pushTestResultMetric(t, r);
},
В Prometheus отправляем объект
t: WebdriverIO.Test с тремя сущностями:
- результат теста (
passed или failed),
- длительность теста,
- исключение в случае ошибки
и сопровождаем их метками-лейблами:
- название теста,
- версия сайта,
- браузер или ОС (
capabilities),
- название тестового набора (
suite).
Prometheus работает по pull-модели, забирая метрики у сервисов самостоятельно. Но наши сервисы представляют собой запущенные на короткое время контейнеры, поэтому мы используем Prometheus exporter. Мы развернули его в Kubernetes — и в него отправляются метрики по результатам каждого прогона автотестов.

Внутри каждой джобы с метрикой отображаются длительность теста, ошибка (если есть), результат и метки.

Из Grafana можно отправлять запросы в Prometheus. Для этого применяется специальный язык
PromQL. Он оперирует векторами из меток, которые мы заполнили ранее:
test_result{capabilities="moonChrome", suite="critical"}
В этом запросе возвращаем результаты критичных тестов, выполненных в Chrome.
Что мы измеряем
Покажу шесть коротких примеров:
- Результаты.
- Ошибки.
- Запуски.
- Длительность.
- Нестабильные (flaky) тесты.
- Покрытие.
1. Результаты
В первую очередь хотим знать, успешно ли пройдены тесты. Изначально у нас было не много тестов и они были довольно простыми. Вот пример работы плагина-визуализатора Statusmap:
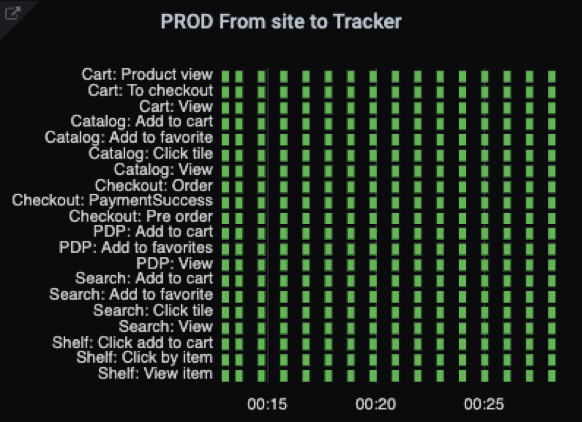
test_result{capabilities="moonChrome", suite="tracker"}
Здесь приведены названия тестов и шкала, на которой в режиме реального времени отображается их статус. На иллюстрации всё зелёное, потому что выбран ночной интервал, когда пользователей мало, сервисы никто не шатает, никто ничего не релизит.
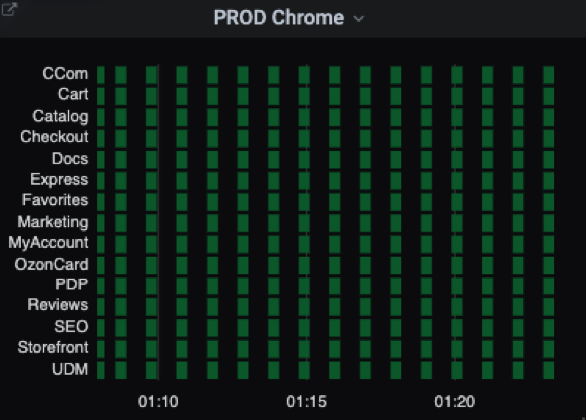
Когда тестов стало больше, такая визуализация перестала нас устраивать. Мы начали группировать тесты по вертикалям и усреднять результаты. Графики получались уже не дискретные, а градиентные: чем больше красного цвета, тем больше тестов упало. А чтобы понять, какие именно тесты упали, можно перейти в Allure, данные которого хранятся у нас в отдельном сервисе.
avg by (describe) (test_result{capabilities="moonChrome", suite="critical"})
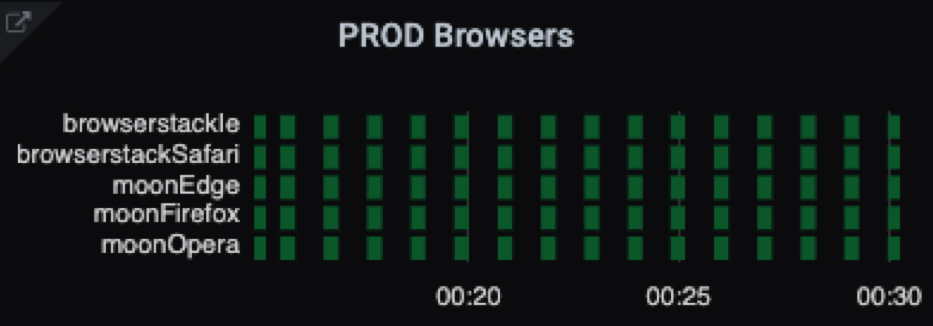
Ещё можно строить полезные графики по разным срезам. Например, мы тестируем различные браузеры — IE, Safari, Edge, Firefox, Opera — и усреднённые результаты выглядят так:
avg by (capabilities) (test_result{suite="browsers"})
Такую визуализацию можно получить и по иным признакам, например по платформам.
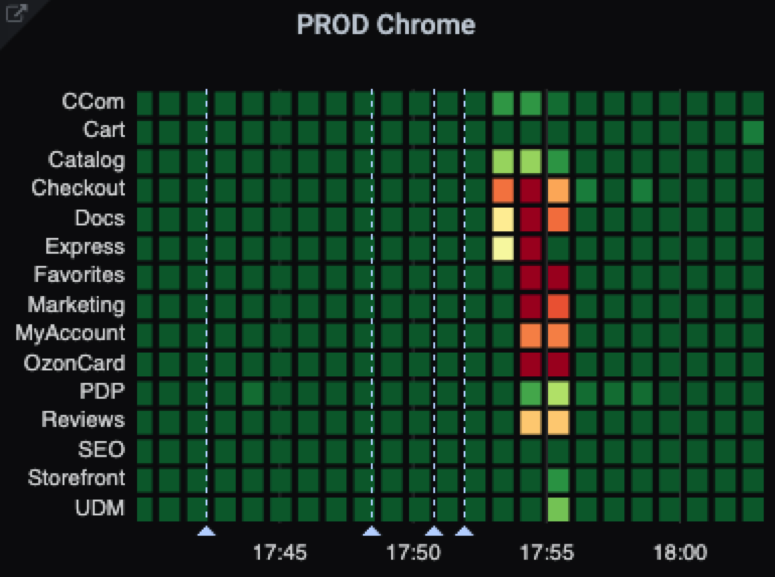
Так выглядит график результатов тестирования по вертикалям в период с 17 до 23 часов:
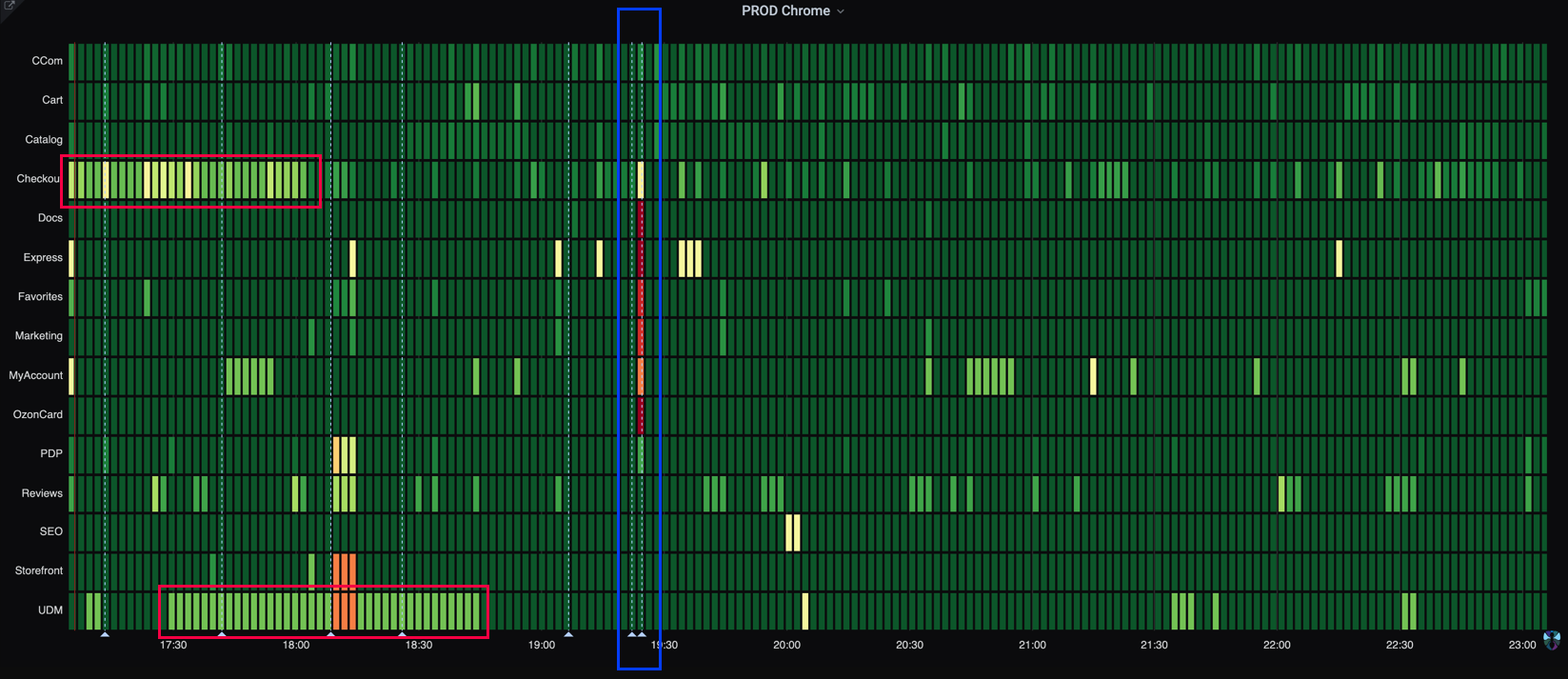
Каждый прямоугольник соответствует интервалу в пять минут. Вертикальные голубые линии — это отметки релизов. Как видите, у двух команд в течение часа что-то шло не так. Обычно мы действуем так: если после релиза тесты красные, то сразу откатываемся и ищем причину проблемы. Бывает и так, что на графиках долго сохраняется красный цвет. Это говорит о поломке либо тестов, либо среды, либо приложения.
В таких ситуациях можно настроить оповещения по PromQL-векторам. Например, у нас они рассылаются, если тест не работает на проде больше четырёх часов. В стейджинг-среде задан порог в 12 часов.
2. Ошибки
Иногда тесты краснеют — и нужно понять, в чём дело. Особенно руководству.
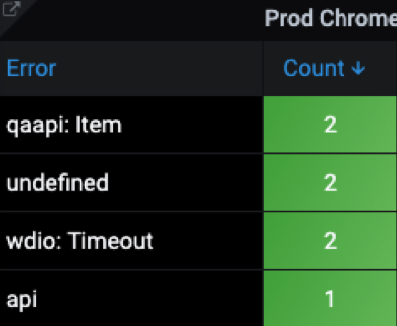
Искать в Allure подробности о каждом упавшем тесте неудобно — хочется видеть всю картину на одном экране. Для этого можно задать свои цвета для сбоев разных категорий тестов и отображать на графике не отдельные тесты, а категории. Например, есть метрика
test_error, по которой можно получить статистику.
count_values ("err", test_error{capabilities="moonChrome", suite="critical"} > 0)
Ошибки в
qaapi: Item говорят о падении на этапе подготовки тестовых данных, ошибки в
wdio: Timeout — о проблеме с тайм-аутами (надо разбираться в Selenium).
Можно выделить следующие категории ошибок:
- ошибки приложений,
- ошибки тестов, инфраструктуры,
- ошибки подготовки тестовых данных.
3. Запуски
Мы запускаем тесты часто и плотно. Интервалы между запусками тестов из одного набора — от шести до 15 минут. Запусков много, и нужно уметь их контролировать.
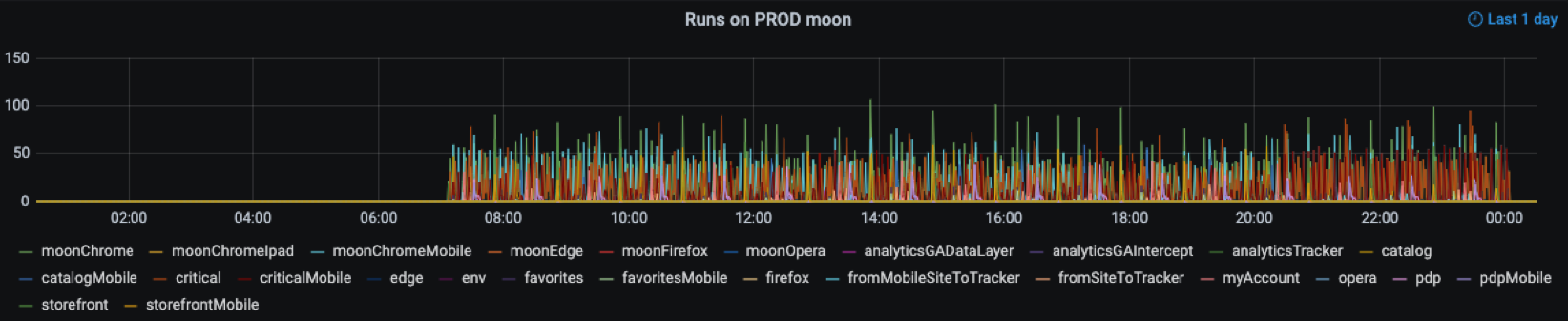
sum by (suite)(changes(push_time_seconds{capabilities=~"moon.*"}[1m]))
Тестируем примерно с 7 утра до 12 ночи. На графике много всплесков, и если кликнуть по одному из значений, то можно увидеть подробную статистику запусков тестов для одной из страниц сайта. Зачем отслеживать этот вид метрик? Контролируя запуски, можно не только проверять расписание тестирования в командах, но и вылавливать возможные ошибки. Приведу пару примеров.
Здесь сразу видно, что одну страницу тестировали слишком часто (каждую минуту). Это пустая трата ресурсов.
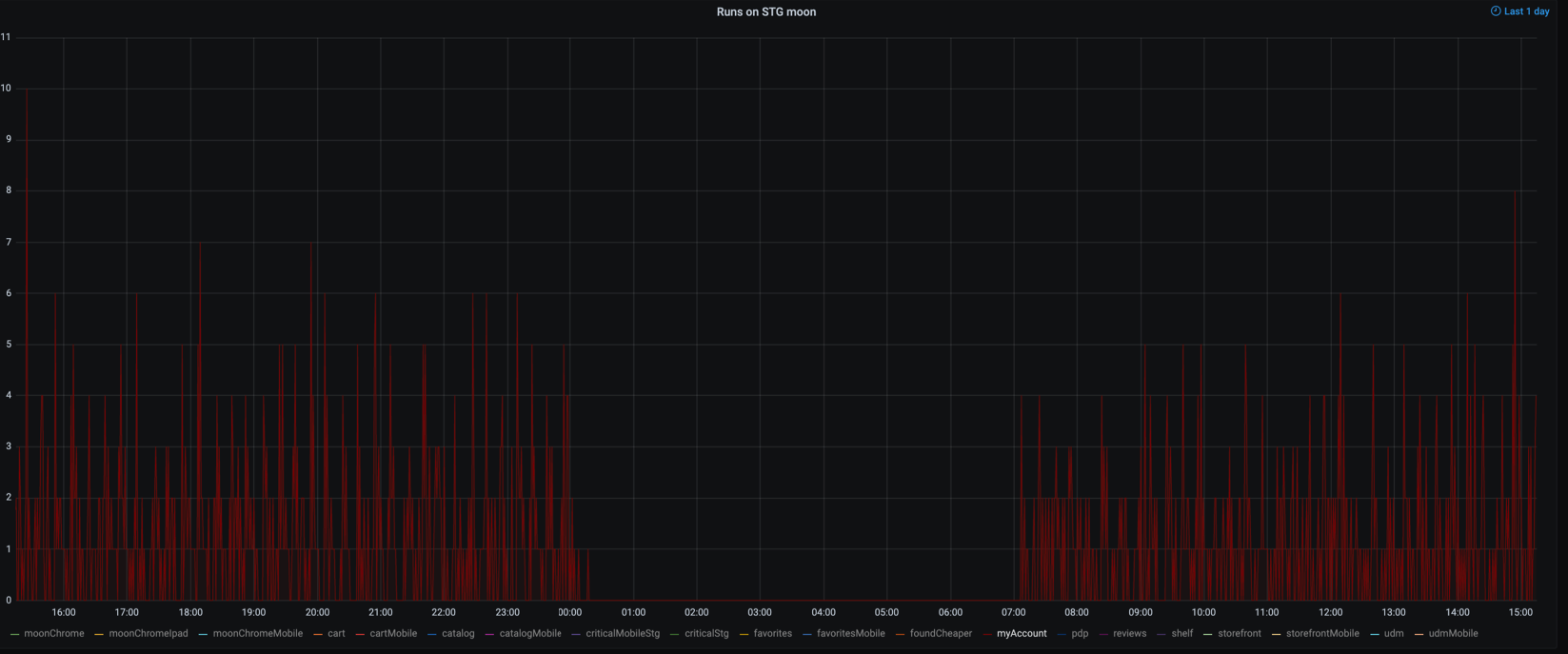
А здесь видно, как у одной команды из-за ошибки в приложении часть тестов прогонялась однократно, а часть — повторялась.
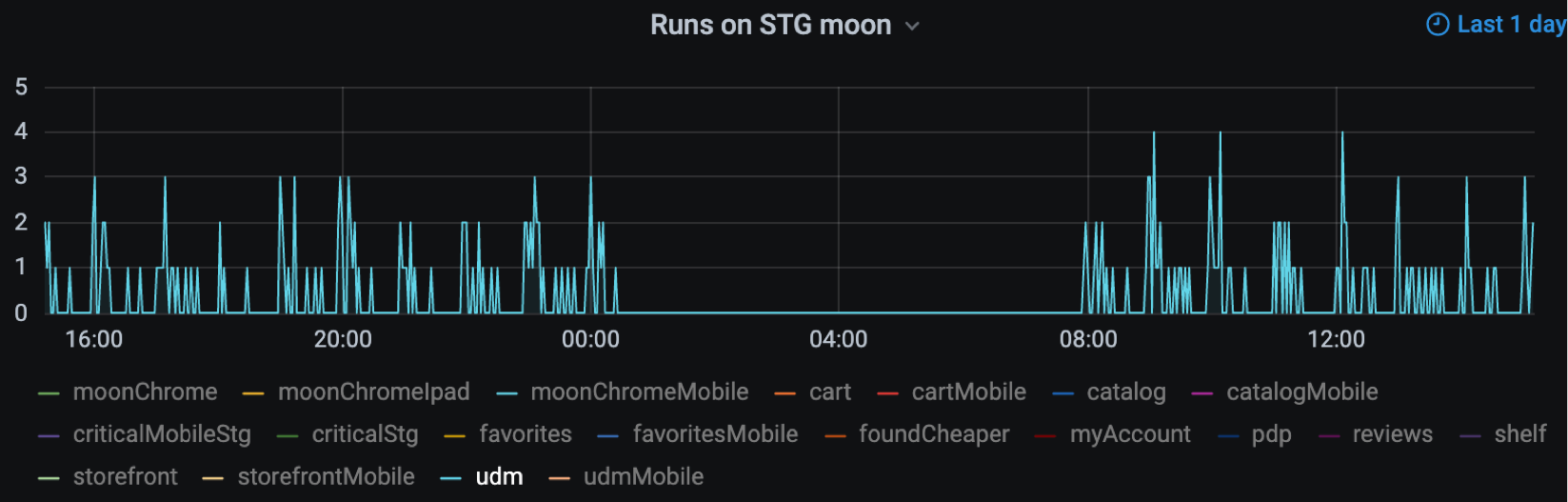
4. Длительность
Время — самый ценный ресурс. Поскольку мы делаем релизы до десяти раз в день, тесты должны быть быстрыми: каждый — не дольше 30 секунд, а весь набор — не дольше пяти минут. Метрика
test duration позволяет контролировать деградацию в приложении, в тестах или инфраструктуре. Делать это можно с помощью такого графика:
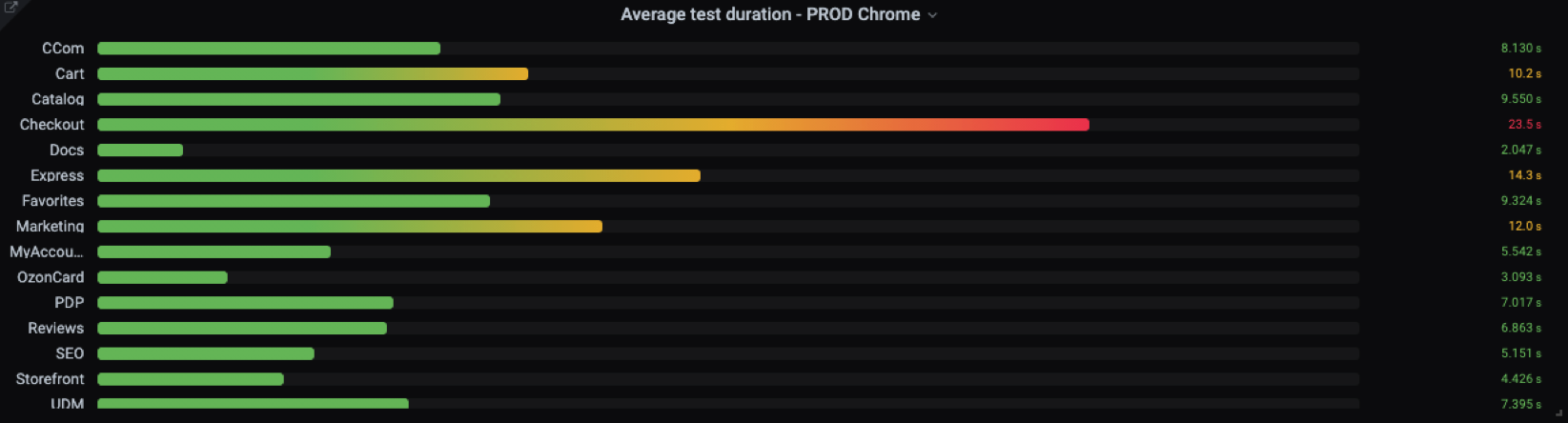
avg by (describe) (test_duration_ms{capabilities="moonChrome", suite="critical"})
Здесь показана средняя продолжительность тестов по командам. Одна команда выделяется — видимо, есть какие-то проблемы в приложении, либо тесты написаны неоптимально.
Тесты могут выполняться слишком долго и из-за проблем с инфраструктурой. Когда мы разворачивали Moon, по этому графику мы отслеживали деградацию:
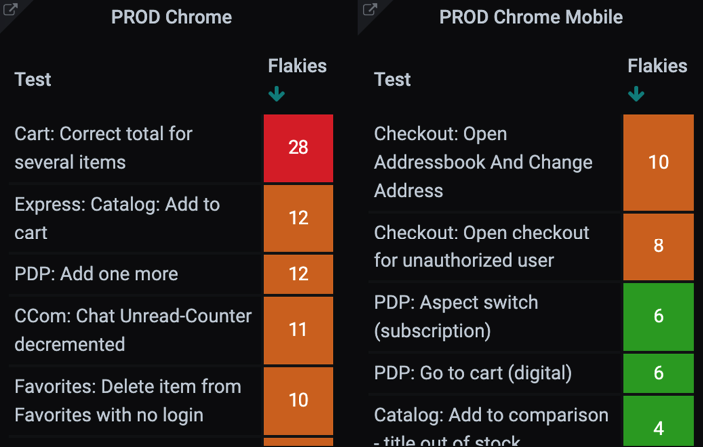
5. Нестабильные (flaky) тесты
Нестабильные тесты — боль и проблема тестировщика. Есть много способов борьбы с ними. Но для начала нужно их выявить. В этом помогает такой запрос:
sum by(it)(changes(test_result{capabilities="moonChrome", suite="critical"}[6h])) > 0
Здесь вычисляется сумма изменений результатов тестов в течение шести часов. Если тест мигает один раз, то значение будет 2. Если мигает один раз в час, то за шесть часов будет 12.
Мигание раз в час для нас допустимо, но, если частота увеличивается, такой тест мы считаем нестабильным, помечаем красным и начинаем разбираться.
6. Покрытие
С сайта в наши аналитические системы постоянно идёт поток данных о действиях пользователей на разных страницах. Каждая страница состоит из нескольких десятков блоков — виджетов. Если пользователю показали виджет, отправляется событие view; если пользователь нажал на что-то — событие click.
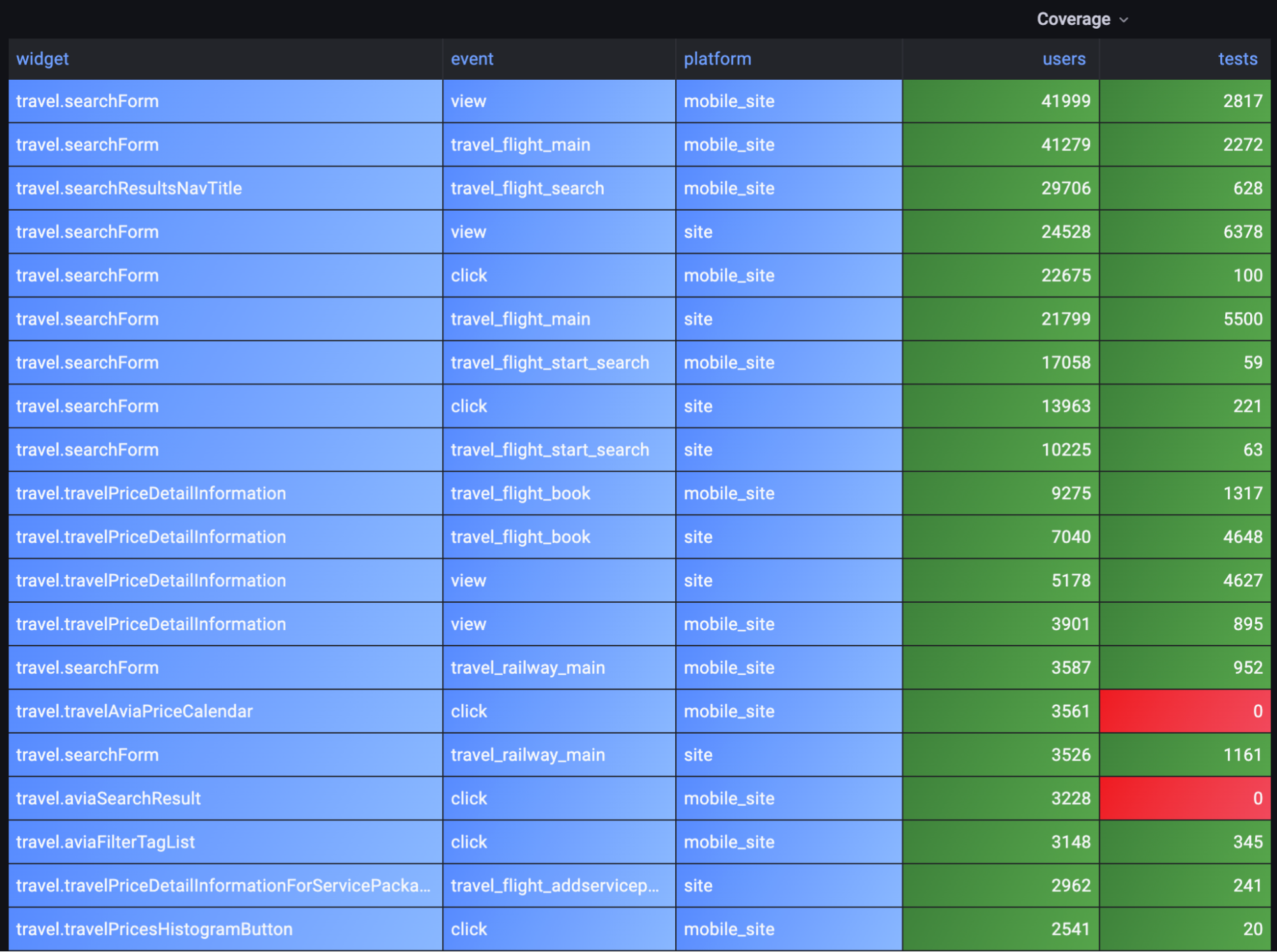
Из аналитических систем можно запрашивать данные для Grafana и строить таблички.
Здесь есть колонки:
- widget — название виджета,
- event — тип события (действие, связанное с виджетом),
- platform — платформа (десктоп или мобильный сайт),
- users — количество кликов от пользователей,
- tests — куда кликают тесты.
Когда по сайту ходят не пользователи, а тесты, их действия сохраняются в другом пространстве имён. Благодаря этому мы можем отличать тесты от людей и оценивать покрытие по графикам. Если тестов нет, ячейки подсвечиваются красным — сразу видно, где у нас пробелы в покрытии. События отсортированы по колонке с событиями пользователей. Это определяет приоритетность при написании новых тестов: чем больше пользователей работают с виджетом, тем нужнее тест.
Собираем всё вместе
Так выглядит дашборд со всеми описанными графиками по одной из вертикалей:
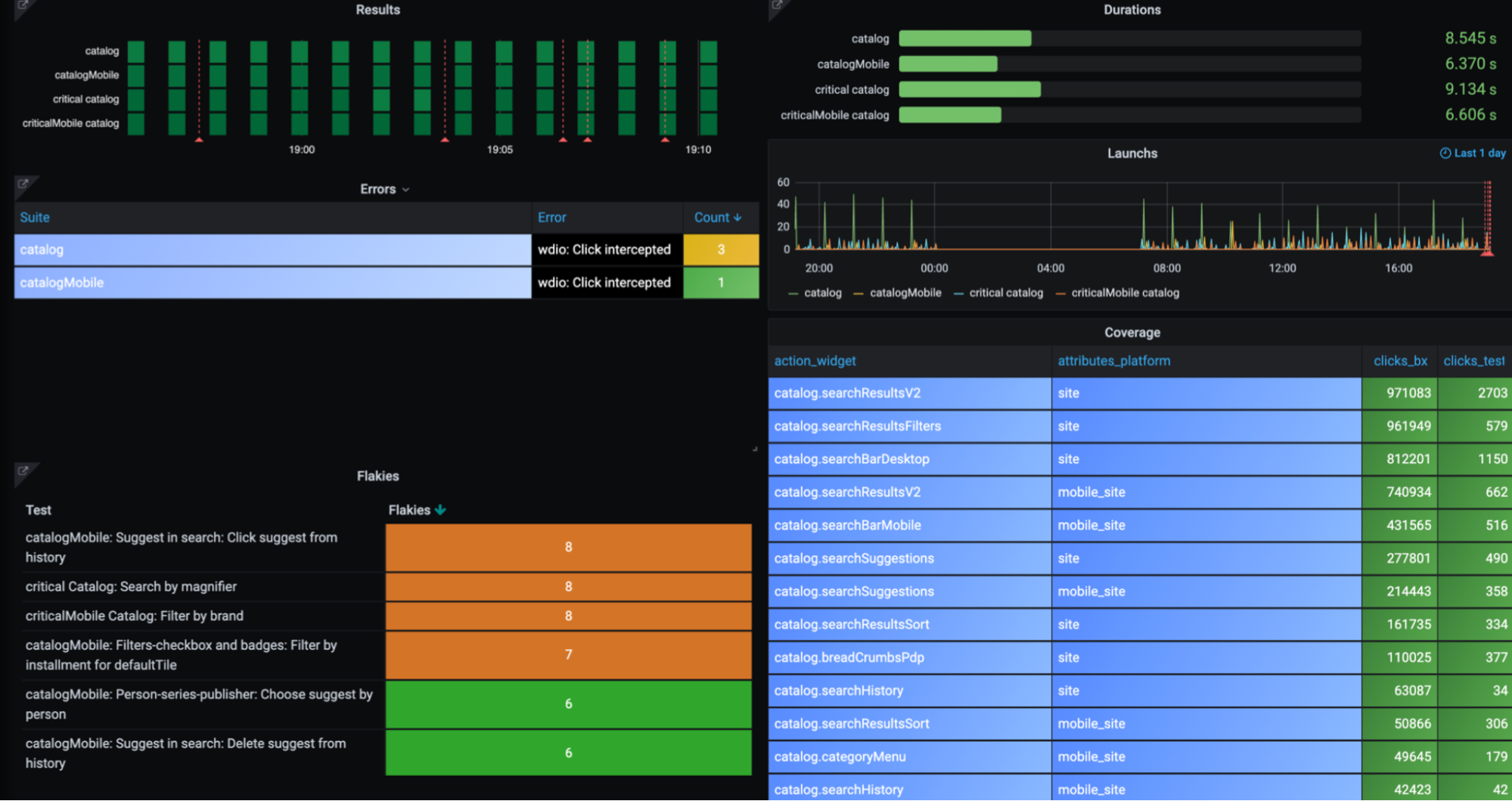
Здесь отображаются результаты тестов, ошибки, нестабильность, длительность, запуски и покрытие. Видно, что тесты прогоняются штатно, основные виджеты покрыты, длительность и количество запусков хорошие. Ошибок не много. В таблице нестабильных тестов нет красного цвета. Можно считать, что у этой команды всё работает как надо.
Другой пример:
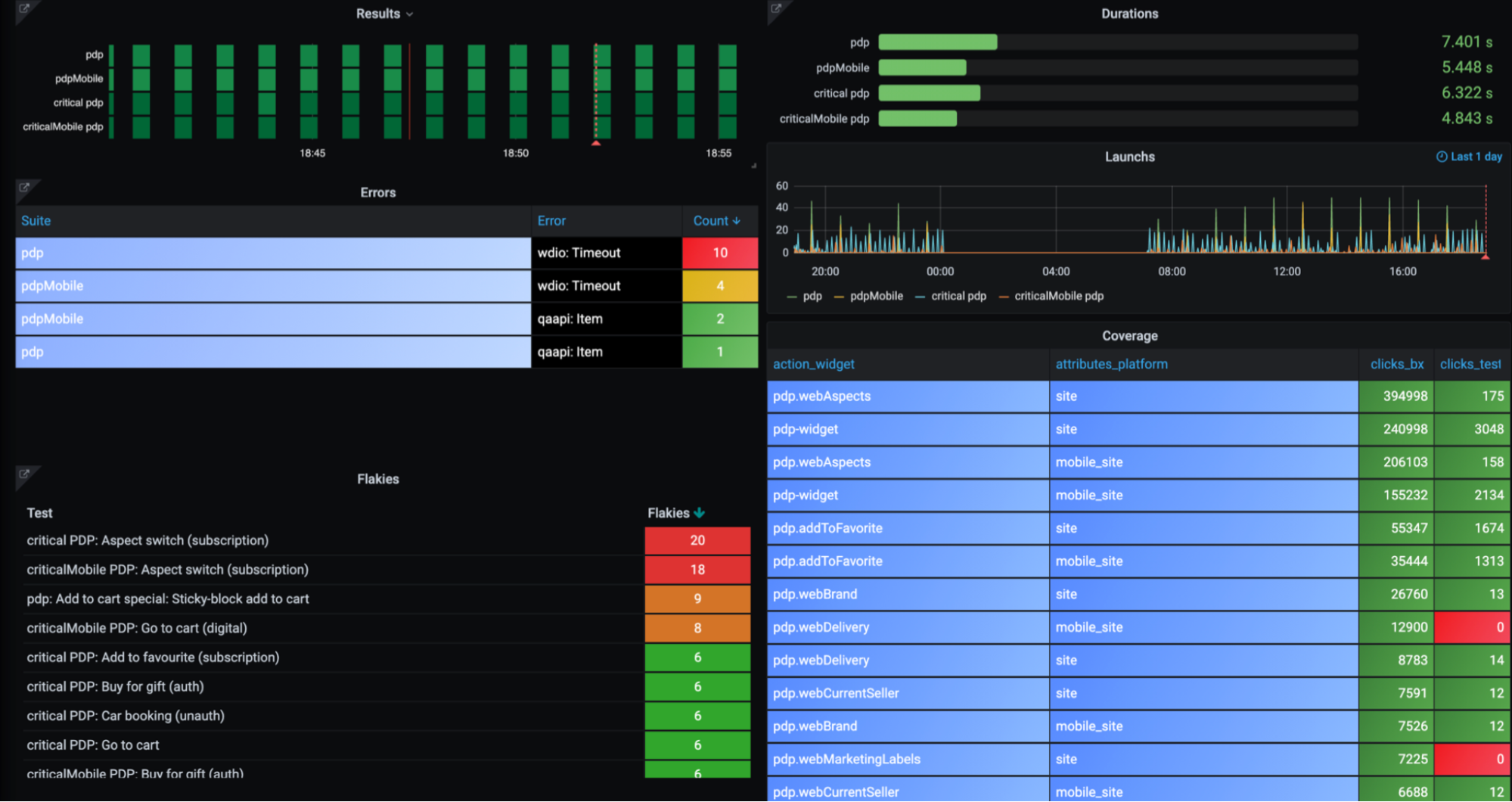
Есть пробелы в покрытии, много ошибок с тайм-аутами, пара совсем нестабильных тестов. Любой тестировщик и тимлид этой вертикали может сразу увидеть, чем необходимо заняться.
Заключение
Учитесь измерять — в тестировании это очень важно. Мы выбрали для себя шесть категорий метрик, но вам не обязательно внедрять сразу все. Начните с чего-то одного, а потом постепенно добавляйте новые метрики, новые срезы. Помните, Grafana — лишь инструмент. Главное — это вы. Всё в ваших руках.