Шардирование было одним из первых механизмов, позволяющих распределять базы данных для повышения их производительности. Последние инновации превратили шардирование в один из лучших механизмов в своем роде.
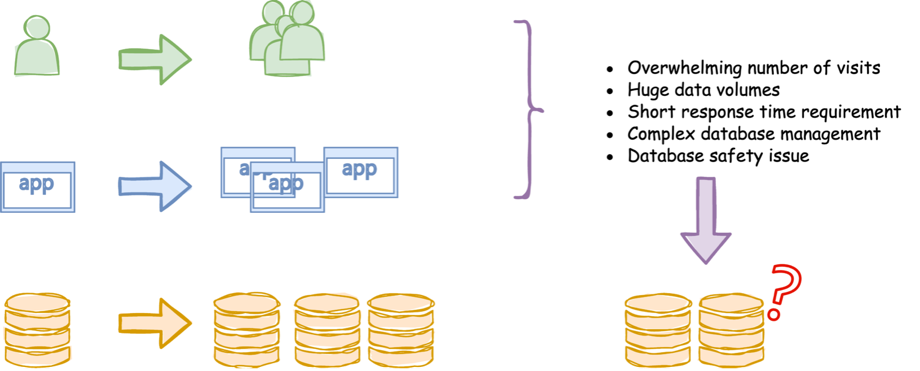
Сегодня базам данных уделяется особое внимание, так как через них компания управляет своим самым ценным архивом: информацией. Всего 30 лет назад большинство данных хранилось на бумаге, магнитной ленте или каких-либо дисках. Поскольку мы производили и потребляли гораздо меньше данных на душу населения, даже на таких носителях нам удавалось эффективно хранить их, управлять ими и обращаться к ним.
Но сегодня с данными складывается совершенно иная ситуация. Смартфоны распространились повсеместно и превратились в необходимую вещь. Вместе со смартфонами увеличилось количество мобильных приложений, и сегодня через них производятся и потребляются такие объемы данных, какие были просто немыслимы 15 лет назад. В такой ситуации серьезно возрастает нагрузка на кластеры баз данных, поскольку им приходится обрабатывать все более серьезные объемы трафика. Некоторые из топовых веб-сайтов и веб-сервисов обрабатывают миллиарды посещений в неделю.
Как справиться с таким невероятным объемом трафика, поступающим в кластер базы данных?
Можно попробовать шардирование. Возможно, вы никогда и не слышали о таком подходе, либо по-быстрому отбраковывали его как старомодное решение, не отвечающее современным вызовам. Сам феномен «шардирования баз данных» едва ли сулит полный набор примочек, какими могли бы похвастаться другие решения, но этот подход определенно эффективен и практичен.
Не так давно этот подход обогатился существенными
инновационными дополнениями, позволившими реализовать продвинутое шардирование с таким набором возможностей, который еще недавно показался бы немыслимым. В частности, стоит упомянуть распределенный SQL, благодаря которому стало гораздо легче выполнять шардирование и управлять шардами. Может быть, именно поэтому так возросла популярность шардирования среди
блокчейновых компаний, стремящихся к максимальному масштабированию.
Фрагментация баз данных
Базы данных существуют уже более 50 лет. Может показаться, что к нашему времени в них уже не внести ничего инновационного, однако фрагментация баз данных – одна из самых быстроразвивающихся вертикалей в современной технической индустрии. По-видимому, сложность, присущая имеющимся ныне инфраструктурам данных, в будущем станет только усугубляться.
Многие современные приложения выстраиваются поверх множества баз данных, зачастую – узкоспециализированные. Единственное приложение может быть оснащено реляционной базой данных для хранения содержимого и обращения к нему (напр. PostgreSQL), базу данных в оперативной памяти (напр. Redis) для кэширования контента, собственную базу данных, например, для ведения временных рядов, а также склад данных для аналитики. Теперь попробуйте вообразить, как все это будет реализовано в бизнесе, работающем со множеством приложений, множеством отделов, в каждом из которых есть собственное приложение или, хуже того, взаимодействующем с разными вендорами.
Как упоминалось выше, данные превратились в один из важнейших активов любого бизнеса. В последнее время развитие технологий баз данных существенно ускорилось, и это, пожалуй, коррелирует с развитием искусственного интеллекта, машинного обучения, блокчейна и облачных технологий, которые также развиваются очень быстро.
По данным сайта
DB-Engines, существует более 350 систем управления базами данных, но на самом деле их гораздо больше, многие даже не попали в этот список.
Согласно
“Базе данных баз данных”, составленной в университете Карнеги-Меллона, в настоящее время существует 792 различных систем управления базами данных, которые заслуживают упоминания.
Такое разнообразие систем управления базами данных (СУБД) демонстрирует, насколько широк спектр возможных требований, которые может предъявлять и должен учитывать бизнес, когда приходится выбирать систему управления базой данных.
Например, банк или финансовая организация может выбрать реляционную СУБД, такую как SQL Server или PostgreSQL, чтобы обеспечить сумму свойств ACID (atomicity, consistency, isolation, durability = атомарность, согласованность, изоляцию, надежность) при транзакциях со структурированными данными. Бизнес, занятый поддержкой крупномасштабной онлайновой многопользовательской игрой или веб-приложениями, работа с которыми требует начинать и завершать сеансы, предпочтет базу данных типа NoSQL, состоящую из ключей и значений – такую как Redis. В свою очередь, бизнес, занимающийся аналитикой в социальных сетях, как правило, пользуются графовыми базами данных. Если же бизнес работает с Интернетом Вещей (IoT), то такой компании подойдет база данных для работы с временными рядами, хорошо поддерживающая данные с сенсоров или сетевые данные.
Если такой выбор вам по душе, то добро пожаловать к столу, поскольку в ближайшие годы на рынке будут появляться все новые и новые решения. Их будут предлагать как новые инновационные стартапы, так и состоявшиеся вендоры баз данных, выпускающие новые продукты или улучшающие уже обкатанные решения.
В ближайшем будущем рынок баз данных ждет только дальнейшая фрагментация. Такая фрагментация сопряжена с серьезными вызовами, навскидку — с совместимостью технологий от разных вендоров, адаптируемостью унаследованных систем, с восстановительной стоимостью.
Для чего требуется шардирование
Традиционные базы данных порой не справляются с обработкой растущих объемов данных и нарастающего трафика запросов. Сегодня очень популярны концепции
NoSQL и NewSQL – соответственно, на рынке баз данных появляется все больше продуктов, вдохновленных этими новыми концепциями. Но их одних недостаточно, чтобы решить все более серьезные проблемы с данными.
Шардирование – это прием, позволяющий разбивать данные на отдельные строки и столбцы, хранимые на отдельных инстансах серверов базы данных. Так удается распределить нагрузку, оказываемую трафиком. Каждая такая малая таблица называется «шард». Некоторые NoSQL-продукты шардируются, таковы, например, Apache HBase или MongoDB. Шардинговая архитектура
встроена в NewSQL-системы.
Рассмотрим NewSQL-архитектуру конкретного типа: как в ней применяется шардирование, и как оно соотносится с современными проблемами OLTP (онлайновой обработки транзакций).
Притом, что существует много решений, позволяющих минимизировать нагрузку на базу данных, шардирование отличается следующими серьезными преимуществами:
Хранение данных распределяется на множестве машин;
Легко сбалансировать между разными шардами нагрузку, которую оказывает трафик;
Значительно улучшается производительность запросов;
Масштабирование баз данных обеспечивается без дополнительной работы;
Традиционные СУБД легко обновлять и эффективно многократно использовать;
При шардировании разные пользователи получают совместный доступ к единственному серверу или к ресурсам для облачных вычислений, поскольку, благодаря использованию прокси, в данном случае поддерживается многоарендный подход (multi-tenancy).
Как шардировать базу данных
Ниже представлен базовый рабочий цикл, позволяющий реализовать шардирование в СУБД. Обсудив устройство и основополагающие идеи этой технологии, ниже мы углубленно расскажем о некоторых наиболее существенных аспектах.
Один из наилучших способов создания шардов таков: данные нужно разделять на множество небольших таблиц. Они также называются «сегментами» (partitions).
Исходную таблицу можно разделить на вертикальные или горизонтальные шарды – то есть, хранить в отдельных таблицах один или более столбцов либо одну или более строк. Эти таблицы можно обозначить ‘VS1’ для вертикальных шардов и ‘HS1’ для плоских шардов. Число соответствует первой таблице или первой схеме. The number represents the first table or the first schema. Then 2, then 3, and so on. When taken together, these subsets of data comprise the table’s original schema.
Вот две ключевые составляющие шардирования:
Шардинговый ключ: конкретное значение в столбце, указывающее, в каком шарде хранится данная строка.
Шардинговый алгоритм: алгоритм, согласно которому ваши данные распределяются в одном или нескольких шардах.
Шаг 1: Проанализировать сценарий запроса и распределение данных, чтобы найти шардинговый ключ и шардинговый алгоритм
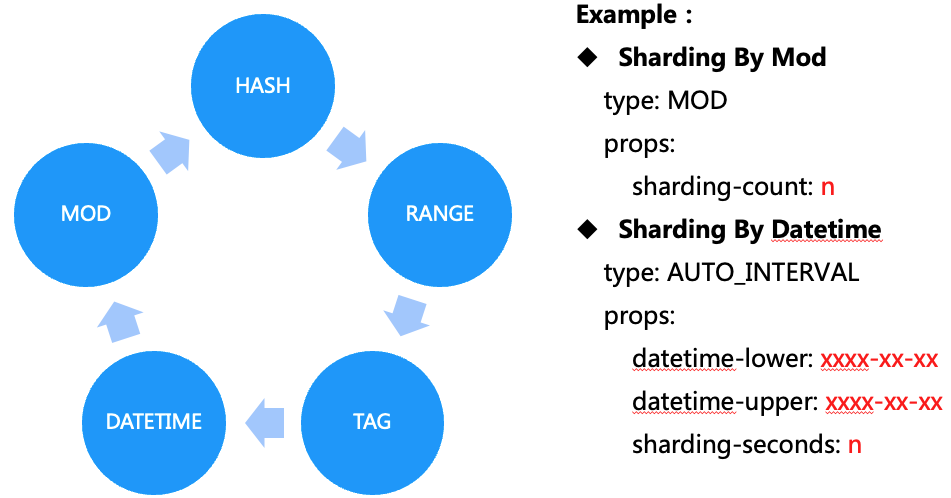
Чтобы определить, в каком шарде будет храниться каждая конкретная строка, шардинговый алгоритм применяется к шардинговому ключу. Различные стратегии шардирования вписываются в разные сценарии. Вот распространенные стратегии:
MOD: сокращенно от «модульный». В данном случае каждая n-ная строка или каждый n-ный столбец отправляются в конкретный шард. Например, алгоритм MOD 3 отправит в первый шард первую, четвертую и седьмую строки, во второй шард – вторую, пятую и восьмую строки, в третий шард – третью, шестую и девятую строки и т. д.
HASH: При хеш-шардировании данные распределяются по шардам равномерным случайным образом. Каждая строка таблицы попадает в тот или иной шард, согласно вычисленному согласованному хешу значений столбцов шарда для данной строки.
RANGE: этот алгоритм отправляет конкретные диапазоны строк или столбцов в отдельные шарды.
TAG: этот алгоритм отправляет в один шард все строки или столбцы, соответствующие конкретному значению.
Например, при шардинговом ключе “ID” и шардинговом алгоритме “ID modulo 2” (который делит все строки на четные и нечетные), строки будут сортироваться примерно так:
Следовательно, ваша задача – спроектировать подходящий алгоритм, использующий шардинговый ключ. Выбранная вами стратегия шардирования существенно повлияет на эффективность запросов, а в дальнейшем – на горизонтальное масштабирование. Неподходящий или плохой шардинговый алгоритм всегда создает в шардах избыточные данные, которые нужно вычислить, что приводит к общему снижению вычислительной производительности.
Ключевыми моментами, которые нужно учитывать, решая, как шардировать базу данных, являются характеристики бизнес-запроса и распределение данных. В каждой базе данных найдутся уникальные факторы, которые повлияют на это решение, но здесь можно рассмотреть для примера несколько сценариев, которые помогут понять, как хороший шардинговый алгоритм эффективно распределяет данные.
RANGE
Например, когда при шардировании таблицы требуется учитывать детальные данные из логов, снабженные метками времени, рекомендуется использовать для шардирования алгоритм RANGE, где шардинговым ключом служит дата создания записи. Причина в том, что традиционно такие подробные записи запрашиваются только в пределах конкретного временного диапазона.
При использовании даты и времени алгоритм RANGE может вызывать другую проблему: обычно сравнительно давние исторические записи обновляются нечасто, а свежие записи и обновляются, и запрашиваются часто. Поэтому большинство запросов будет попадать в шард с самыми свежими записями. Таким образом, большинство запросов будут конкурировать друг с другом за получение исключительных прав на обновление данных.
MOD
Шардинговый алгоритм MOD способен эффективно избегать такой жаркой конкуренции. Он делит строки по принципу ‘shardingKey MOD количество шардов’. Новейшие строки будут распределяться по разным шардам, чтобы за эти строки не разыгрывалась конкуренция. Когда шардинговый ключ – это строковое значение (потенциально не подлежащее раскрытию), можно воспользоваться алгоритмом HASH. Он создает значение, которое алгоритм MOD может использовать для распределения данных по шардам.
TAG
Но случается и так, что данные предпочтительно шардировать по значению ячейки. В таком случае вам подойдет шардинговый алгоритм TAG. Предположим, что, ради соответствия общему регламенту по защите данных (GDPR) вы хотите хранить все данные, относящиеся к ЕС, на сервере, расположенном в ЕС. Как в таком случае шардировать распределенную базу данных?
Если администратор БД использует шардинговый алгоритм TAG, то строки с данными из помеченных стран могут направляться на конкретные шарды, физически расположенные в подходящей стране. Чтобы выяснить, сколько записей будет при этом затронуто, наша щардинговая система базы данных для ответа на такой запрос всего лишь должна вернуть COUNT(*) из шарда, относящегося к ЕС:
SELECT COUNT(*) FROM registrant_table WHERE region = "EU". Распределенный запрос, который должен вычислить конечный результат для целой распределенной системы, превращается в простой единичный запрос от одного шарда.
Здесь нет панацеи на все случаи жизни. Чтобы добиться максимально возможной производительности, уделите время тщательному анализу вашего конкретного бизнес-сценария. Если вас интересует быстрый старт, то распределенная шардинговая система БД обычно может подхватить распространенную стратегию, которая подойдет для большинства практических случаев.
Шаг 2: Миграция имеющихся данных
Если вы решили реализовать шардирование, то необязательно переносить все оригинальные данные в шардинговый кластер. Это совсем не просто, так как вы столкнетесь со следующими проблемами:
Как шардировать данные, если бизнес работает круглосуточно и без выходных
Как воспроизвести инкрементные данные в новом шардинговом кластере
Как сравнить данные между оригинальной базой данных и новым шардинговым кластером
Как найти наилучший момент, чтобы перенаправить трафик в новый шардинговый кластер
Правда, если вы решите перенести в шарды исторические данные, то традиционно это делается так:
Во-первых, перед переносом исторических данных в шардинговый кластер новой базы данных их нужно сегментировать при помощи вашего шардингового алгоритма. Рекомендую пользоваться программой для автоматического переноса данных, которая автоматически выполнила бы все необходимые SQL-запросы.
Во-вторых, запустите платформу или программу, которая вытянет и распарсит лог базы данных – так можно будет понять, какие изменения возникли в процессе сегментирования, и применить эти изменения в новом шардинговом кластере (сделать шарды с инкрементными данными).
В-третьих, выберите стратегию проверки данных, чтобы сравнить данные в оригинальной базе данных и новом шардинговом кластере. Такие стратегии отличаются гибкостью и обеспечивают любые варианты от «очень точно» до «очень быстро» — либо позволяют уравновесить эти крайности. Именно от вас зависит, хотите ли вы сравнить варианты с точностью до ячейки, либо просто проверить общую сумму. Если нужно подобрать максимально точную стратегию проверки данных, то наиболее ресурсоемкой будет проверка всех строк по порядку, тогда как проверка только суммы по строкам для оригинальных и новых кластеров потребует меньше всего времени – но придется пожертвовать точностью. Другие стратегии, например, CRC32, позволяют соблюсти баланс между точностью и скоростью.
Шаг 3: Перебросить трафик на новый кластер
Если предположить, что все вышеописанные шаги прошли гладко, то на следующем этапе перебросим онлайновый трафик на ваш новый шардинговый кластер. Это должно быть сделано, пока невозможна запись в кластер баз данных, так, что два множества данных остаются согласованными и поддерживаются опциональные запросы. Как правило, этот шаг выполняется в период минимальной загруженности.
Для обеспечения согласованности распределенных данных все запросы на обновление должны быть запрещены, но запросы при этом разрешаются, поскольку запрос не вносит никаких изменений в распределенную систему.
Этот процесс достаточно прямолинеен, но обработка каждого из его этапов может оказаться нетривиальной. Если переход автоматизирован, то минимизируется длительность простоя; однако, при этом рекомендуется известная осторожность, поскольку вы будете обращаться с ценными данными.
В данном случае отрадно, что не вы первый сталкиваетесь с такими вызовами. Благодаря опенсорсным проектам, мы можем стоять на плечах гигантов.
Среди основных возможностей
Apache ShardingSphere (контрибьютором которого является автор поста) – возможность проведения всего шардирования целиком. В этом инструменте предусмотрены различные шардинговые стратегии, обеспечена миграция данных, решардинг и управление имеющимися шардами.
Также здесь предоставляются и более продвинутые функции – они помогают с устранением проблем, рассмотренных в следующем разделе. В качестве бонуса Apache ShardingSphere может похвастаться активным сообществом – а значит, что большинство ваших проблем уже кем-то решались.
В чем заключается качественное шардирование
Теперь вы понимаете, каков поток задач при шардировании, и какие шаги необходимы при шардировании базы данных. Но каковы признаки хорошего шардирования?
Не будем вдаваться в детали сомнительных теорий или в контекст и требования, специфичные для конкретных сценариев. В целом хорошее шардирование обладает шестью качествами.
Такое шардирование легко настраивается, при нем легко понять, изменился ли администратор БД, выполняющий операции. Хорошее шардирование характеризуется высокой доступностью, возможностью эластичного горизонтального масштабирования, высокой производительностью распределенных систем, отслеживаемостью и низкими издержками при миграции данных.
При наличии всех этих шести характеристик шардирование можно считать идеальным, но в целом его качество зависит и от выбранного вами шардингового клиента.
Используем шардирование и репликацию
Кроме основного потока задач, описанного выше, разберитесь в перечисленных ниже элементах, поскольку сценарии работы с базой данных разнообразны, а по мере масштабирования приложения и ваши потребности будут меняться.
Кроме того, повысить производительность и улучшить масштабируемость базы данных можно путем репликации. Репликация подразумевает дублирование узлов базы данных, причем, такие узлы действуют независимо друг от друга. Данные, записанные на одном узле, затем реплицируются на его узле-дублере.
Вообще, как профессиональные разработчики, так и программисты, ведущие проект для души, выжимают из баз данных максимум, чтобы обеспечить высокую доступность и производительность. Тем не менее, если архитектура предусматривает шардирование и репликацию, это может осложнять как управление базой данных, так и стратегию маршрутизации.
Предположим, у каждого шарда есть узлы-реплики. Получается структура, напоминающая приведенный ниже график. Если у одного узла будет более одной реплики, то для всех приложений, обращающихся к базе данных, ситуация быстро деградирует.
Итак, чем же отличаются шардирование и репликация? Как рассмотрено выше, при шардировании одна таблица дробится на множество более мелких – так получаются многочисленные шарды. При репликации, в свою очередь, создается много реплик исходной таблицы. В каждой реплике будет содержаться полный набор данных с оригинала (ведущего узла).
Шардирование помогает пользователю сбалансировать нагрузку при работе с данными, существующими на множестве серверов – так обеспечивается масштабируемость. Репликация, в свою очередь, позволяет создавать резервные копии основной базы данных, чтобы увеличить доступность системы. Две эти архитектуры разные, и они привносят разные преимущества в распределенную систему. Рассуждая именно так, некоторые пользователи хотят одновременно располагать обеими этими возможностями, поэтому довольно часто встречаются смешанные архитектуры, одновременно опирающиеся как на шардирование, так и на репликацию.
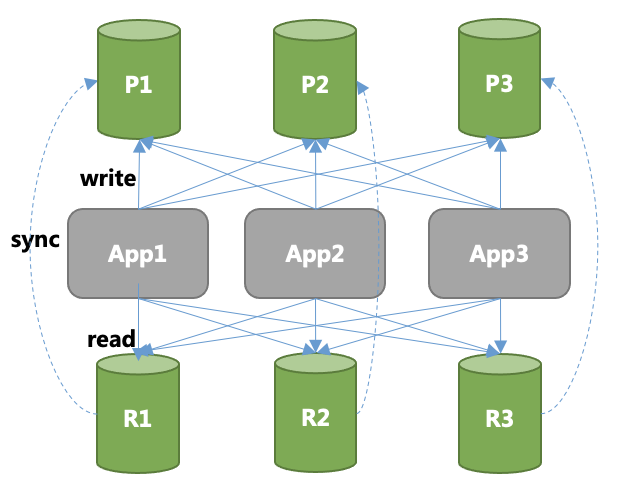
Как показано на следующей иллюстрации, пользователь, возможно, захочет шардировать по разным серверам (например, P1, P2, P3) одну базу данных, содержащую колоссальный объем информации. Каждый запрос также будет разбиваться по разным шардам, ради улучшения показателей TPS (транзакции в секунду) или QPS (запросы в секунду) данной распределенной системы. Однако, если один из шардов откажет, то доступность системы снизится до 2/3. Более того, понадобится немало времени, чтобы поднять еще одну копию оффлайновой версии, часть данных будет потеряна, и последствия будут тяжелыми. Эффективный способ повысить доступность шардированной системы – организовать репликацию каждого шарда, то есть, вышеупомянутых ведущих узлов P1, P2, P3.
Вышеописанное решение проиллюстрировано ниже, и нужно обратить внимание на R1, R2, R3. Когда P1 недоступен, его реплика R1 будет повышена в правах до ведущего узла, чтобы влиться в полноценное обслуживание бизнеса. Это безопасный вариант, продуманный с учетом того, что, чем меньше продлится отказ, тем меньше будут потери для вашего бизнеса и услуг.
Идея кажется отличной, но топология такой распределенной шардированной системы базы данных осложняет посещение приложения. Допустим, каждому ведущему узлу принадлежит две реплики. В таком случае, сеть, состоящая из P1, P2, P3 и шести их реплик запутает и обременит разработчиков, поставив, например, такие вопросы: какой из ведущих узлов лучше всего подходит для данного запроса? Как посетить одну из реплик? Как сбалансировать нагрузку между разными репликами? Кто поможет мне перенаправить данный запрос, если ведущий узел окажется неработоспособен?
В нашем гипотетическом сценарии ответственность разработчика – в том, чтобы эффективно писать код для бизнеса. У описанной здесь примечательной архитектуры в самом деле есть достоинства, но она слишком сложна в использовании и поддержке.
Как вынести эту сложность за пределы приложения?
Обычно существует два типа клиентов или режимов доступа, предоставляемых на выбор пользователям, плюс еще один «бонусный» тип клиента. Стимулом к шардированию может послужить некий фактор, требующий соединения со специализированной базой данных, либо подключение вашего приложения к прокси-приложению, которое маршрутизирует данные.
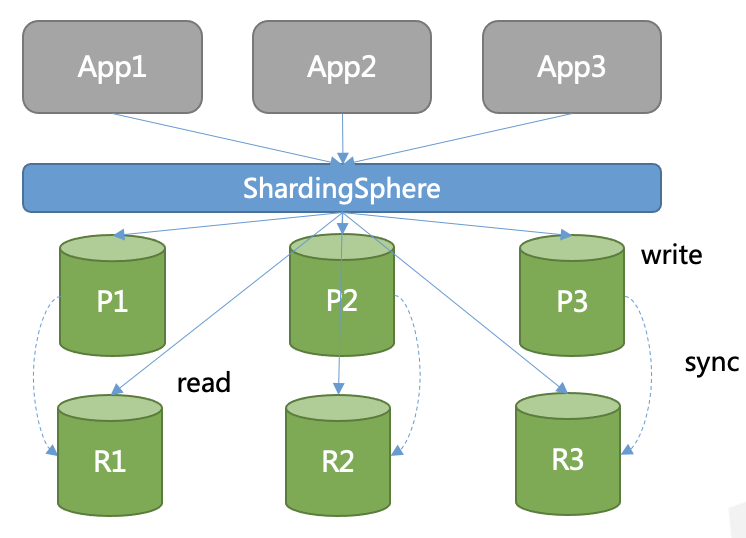
Среди доступных режимов шардирования есть сравнительно новая концепция «прицеп» (sidecar), впервые возникшая в сервисных сетях. Проще говоря, это прокси-инстанс, развертываемый с целью обработки коммуникации, мониторинга, т.д. – наряду с другими службами. Концептуально такой сервис похож на коляску мотоцикла. Подобно коляске, он подцепляется к главному приложению и обеспечивает для него вспомогательные функции.
Если вместо прицепа воспользоваться выделенным драйвером или прокси, то вся система будет действовать и выглядеть как единый сервер базы данных, который поможет пользователям управлять имеющимся кластером. Таким образом, эти сложные топологии посещения не отразятся на приложениях, и данные топологии не придется рефакторить, чтобы адаптировать их к новому фреймворку.
Заключение и существующие тренды
Шардирование – это один из способов справиться с новыми вызовами, возникающими в ходе эволюции сетевых приложений. Среди других подобных решений – база данных как услуга (DBaaS) или облачная база данных, новые архитектуры базы данных или просто дедовский метод – увеличить количество баз данных, используемых в качестве хранилищ информации.
Итак, мы сделали полный круг и вернулись к началу. Надеюсь, этот опус послужил вам введением в шардинговую архитектуру и помог с ней познакомиться, тем более, если вы уже слышали о таких архитектурах, но отметали их из-за кажущейся старомодности. Возможно, теперь ваше мнение изменилось.
Мне не нравится слово «мода», поскольку мода кажется мне чем-то мимолетным, сегодня она актуальна, а завтра ее нет. В то время, что именно так и бывает со многими вещами в жизни, и особенно в технологиях, я предпочитаю судить о технологии по ее практичности, эффективности и экономности при конкретном сценарии.
При этом хорошо бы всегда откликаться на новые тенденции, не забывая, что порой уже имеющиеся и зрелые технологии предлагают наилучшее возможное решение.