 на главную сниппетов
на главную сниппетов
Настроить репликацию в MySQL просто, но управление ею в продакшне никогда не было легкой задачей. Даже с новым автоматическим позиционированием GTID все может пойти не так, если не знать, что делать. После настройки репликации может произойти всякое. Легко допустить ошибки, которые приведут к катастрофическим последствиям для ваших данных.
В этой статье мы рассмотрим некоторые из наиболее распространенных ошибок, допускаемых при репликации MySQL, и то, как их можно предотвратить.
Настройка репликации
При настройке репликации MySQL необходимо загрузить ведомые (slave) узлы датасетом с ведущего (master) узла. В таких решениях, как Galera cluster, данная операция выполняется автоматически с помощью выбранного вами метода. При репликации MySQL это нужно делать самостоятельно, поэтому, естественно, вы берете стандартный инструмент резервного копирования.
Для MySQL существует огромное количество инструментов резервного копирования, но чаще используется mysqldump. Mysqldump создает логический бэкап датасета вашего мастера. Это означает, что копия данных будет не двоичной, а большим файлом, содержащим запросы для воссоздания датасета. В большинстве случаев это должно предоставить вам (почти) идентичную копию ваших данных, но бывают случаи, когда это не так — из-за того, что дамп создается для каждого объекта. Это означает, что еще до начала репликации ваш датасет не совпадает с мастером.
Существует несколько настроек, чтобы сделать mysqldump более надежным, например, выполнять дамп в виде одной транзакции, а также не забывать о включении рутин и триггеров:
mysqldump -uuser -ppass --single-transaction --routines --triggers --all-databases > dumpfile.sqlДля проверки того, совпадает ли ваш слейв на 100%, рекомендуется использовать pt-table-checksum после настройки репликации:
pt-table-checksum --replicate=test.checksums --ignore-databases mysql h=localhost,u=user,p=passЭтот инструмент рассчитает контрольную сумму для каждой таблицы на мастере, реплицирует команду на слейв, который затем выполнит ту же операцию с контрольной суммой. Если какая-либо из таблиц не совпадает, это должно быть четко видно в таблице контрольных сумм.
Использование неправильного метода репликации
По умолчанию в MySQL использовался так называемый метод командной репликации. Он представляет собой именно то, чем он является: поток репликации каждой команды, выполняемой на мастере, которая будет воспроизводиться на слейве. Поскольку сам MySQL является многопоточным, а его (традиционная) репликация — нет, то порядок выполнения команд в потоке репликации может не совпадать на 100%. Также, повтор команд может дать разные результаты, если они не выполняются в одно и то же время.
Это приводит к тому, что датасеты мастера и слейва могут различаться из-за дрейфа данных. Долгие годы это не было проблемой, поскольку мало кто запускал MySQL с большим количеством одновременных потоков, но в современных многопроцессорных архитектурах это становится вполне вероятным при обычной повседневной нагрузке.
Ответом MySQL стала так называемая построчная репликация. При построчной репликации данные реплицируются везде, где это возможно, но в некоторых исключительных случаях все же используются команды. Хорошим примером может служить изменение DLL таблицы, где при репликации нужно будет скопировать каждую строку таблицы. Поскольку это неэффективно, такой оператор будет реплицироваться традиционным способом. Когда репликация на основе строк обнаружит дрейф данных, она остановит ведомый поток, чтобы не ухудшить ситуацию.
Существует метод, занимающий промежуточное положение между этими двумя способами: репликация в смешанном режиме. При этом типе репликации всегда будут реплицироваться команды, за исключением случаев, когда запрос содержит функцию UUID(), использованы триггеры, хранимые процедуры, UDF и некоторые другие исключения. Смешанный режим не решит проблему дрейфа данных, и его следует избегать вместе с командной репликацией.
Круговая репликация
Выполнение репликации MySQL с несколькими мастерами может понадобиться, если у вас есть среда с разными центрами данных. Поскольку приложение не может ждать, пока мастер из другого центра данных подтвердит вашу запись, предпочтительнее использовать локальный мастер. Обычно для предотвращения конфликтов данных между мастерами используется автоматическое инкрементирование. Наличие двух мастеров, выполняющих запись друг другу таким образом, считается общепринятым решением.

Однако, если вам нужно записать несколько центров обработки данных в одну и ту же базу данных, вы получите несколько мастеров, которым необходимо записать свои данные друг другу. До версии MySQL 5.7.6 не существовало метода для выполнения mesh-репликации, поэтому альтернативой было бы использование круговой кольцевой репликации.

Кольцевая репликация в MySQL проблематична по следующим причинам: задержка, высокая степень доступности и дрейф данных. При записи некоторых данных на сервер A, они должны проделать три прыжка, чтобы оказаться на сервере D (через серверы B и C). Поскольку (традиционная) репликация MySQL является однопоточной, любой долго выполняющийся запрос в процессе репликации может застопорить все кольцо. Кроме того, если какой-либо из серверов выйдет из строя, то кольцо будет разорвано. В настоящее время не существует программного обеспечения для преодоления отказов, способного восстанавливать структуры кольца. Также может произойти дрейф данных, когда данные записываются на сервер A и в то же время изменяются на сервере C или D.

В целом, круговая репликация не является подходящим вариантом для MySQL, и ее следует избегать любой ценой. Galera будет хорошей альтернативой для выполнения записей в нескольких центрах обработки данных, поскольку она специально была разработана с учетом этого.
Замедление репликации при больших обновлениях
Часто при выполнении различных служебных пакетных заданий выполняются разнообразные задачи, начиная от очистки старых данных и заканчивая вычислением усредненных результатов "лайков", полученных из другого источника. Это означает, что через определенные промежутки времени задание будет создавать много активности в базе данных и, скорее всего, записывать много данных обратно в базу данных. Естественно, это подразумевает, что и активность в потоке репликации будет возрастать в такой же степени.
Командная репликация будет выполнять именно те запросы, которые используются в пакетных заданиях, поэтому если запрос занял полчаса для обработки на мастере, то поток на слейве будет остановлен как минимум на такое же время. Это означает, что никакие другие данные не смогут реплицироваться, и слейв-узлы начнут отставать от мастера. Если это превышает пороговое значение вашего инструмента аварийного переключения или прокси-сервера, он может удалить эти слейв-узлы из числа доступных узлов кластера. При командной репликации это можно предотвратить, обрабатывая данные для задания небольшими партиями.
Теперь, возможно, вы подумаете, что построчная репликация не подвержена этому, поскольку она будет реплицировать информацию о строке, а не о запросе. Это отчасти верно, поскольку при изменениях DDL репликация возвращается к формату на основе команд. Также большое количество операций CRUD повлияет на поток репликации: в большинстве случаев это все еще однопоточная операция, и поэтому каждая транзакция будет ждать, чтобы предыдущая была воспроизведена через репликацию. Это означает, что при высоком параллелизме на мастере слейв может застопориться из-за перегрузки транзакциями во время репликации.
Для того чтобы это обойти, и MariaDB, и MySQL предлагают параллельную репликацию. Реализация может отличаться в зависимости от производителя и версии. MySQL 5.6 использует параллельную репликацию при условии, что запросы разделены по схемам. MariaDB 10.0 и MySQL 5.7 могут обрабатывать параллельную репликацию по схемам, но при этом имеют иные ограничения. Если вы перегружены записью, то выполнение запросов через параллельные слейв потоки может ускорить процесс репликации. В противном случае лучше придерживаться традиционной однопоточной репликации.
Изменения схемы
Выполнение изменений схемы на запущенной в продакшн системе всегда доставляет много хлопот. Это связано с тем, что DDL-изменение чаще всего блокирует таблицу и данная фиксация снимается только после применения этого изменения. Все становится еще хуже, когда вы начинаете реплицировать эти DDL-изменения через MySQL-репликацию, в результате чего поток репликации дополнительно затормаживается.
Часто используется обходной путь — сначала применить изменение схемы к слейв узлам. Для командной репликации такое решение прекрасно подходит, но для построчной - это действует только до определенной степени. Построчная репликация допускает присутствие дополнительных столбцов в конце таблицы, поэтому, пока она записывает первые столбцы, все будет в порядке. Сначала примените изменение ко всем слейвам, затем выполните аварийное переключение на один из них, а потом примените изменение к мастеру и подключите его в качестве слейва. Если ваше изменение включает в себя вставку столбца в середину или его удаление, то это будет выполняться с помощью построчной репликации.
Существуют инструменты, позволяющие выполнять изменения схемы в режиме онлайн более надежно. Percona Online Schema Change (известная как pt-osc) создаст теневую таблицу с новой структурой, вставит новые данные с помощью триггеров и выполнит обратное заполнение данных в фоновом режиме. После создания новой таблицы она просто поменяет старую таблицу на новую внутри транзакции. Это работает не во всех случаях, особенно если в существующей таблице уже есть триггеры.
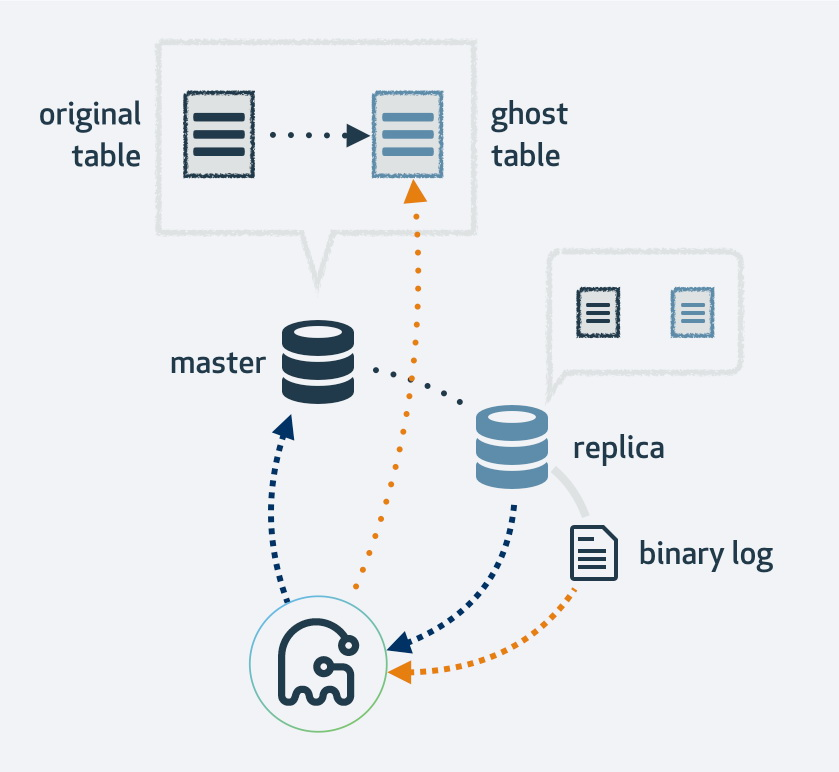
Альтернативой является новый инструмент Gh-ost от Github. Этот онлайн-инструмент для изменения схемы сначала создаст копию существующего макета таблицы, изменит таблицу в соответствии с новой структурой, а затем подключит этот процесс как реплику MySQL. Он будет использовать поток репликации для поиска новых строк, которые были вставлены в исходную таблицу, и в то же время будет выполнять заполнение таблицы. После завершения заполнения исходная и новая таблицы поменяются местами. Естественно, все операции с новой таблицей также попадают в поток репликации, поэтому на каждой реплике миграция происходит в одно и то же время.
Таблицы памяти и репликация
Раз уж мы затронули тему DDL, то к распространенным здесь проблемам относится создание таблиц памяти. Таблицы памяти — это неперсистентные таблицы, их структура остается, но они утрачивают свои данные после перезапуска MySQL. При создании новой таблицы памяти как на мастере, так и на слейве, у обоих она будет пустой, и все это будет работать совершенно нормально. После перезапуска любого из них таблица будет очищена и возникнут ошибки репликации.
Построчная репликация прервется, когда данные в слейве вернут разные результаты, а командная будет прервана, когда она попытается вставить данные, которые уже существуют. Для таблиц памяти такое нарушение репликации встречается часто. Исправить это легко: просто создайте свежую копию данных, измените движок на InnoDB, и тогда репликация станет безопасной.
Установка переменной read_only в True
Как мы описывали ранее, отсутствие одинаковых данных на слейвах может нарушить репликацию. Часто это происходит из-за того, что что-то (или кто-то) изменяет данные на слейв-узле, но не на мастере. Когда данные мастер-узла изменятся, они будут реплицированы на слейв, который не сможет загрузить изменения, что приведет к сбою репликации.
Есть простое решение: установите переменную read_only в true. Это запретит кому-либо вносить изменения в данные, кроме пользователей репликации и рут-пользователей. Большинство менеджеров по устранению отказов устанавливают этот флаг автоматически, чтобы предотвратить запись пользователей на используемый мастер во время аварийного переключения. Некоторые из них даже сохраняют этот флаг после восстановления работоспособности.
Это все же оставляет возможность рут-пользователю выполнить ошибочный CRUD-запрос на слейве. Чтобы этого не произошло, начиная с версии MySQL 5.7.8 существует переменная super_read_only, которая блокирует обновление данных даже для рут-пользователя.
Активация GTID
При репликации MySQL очень важно запускать слейв с правильной позиции в бинарном логе. Получить эту позицию можно при создании резервной копии (xtrabackup и mysqldump поддерживают это) или когда вы остановили синхронизацию на узле, копию которого вы создаете. Запуск репликации с помощью команды CHANGE MASTER TO будет выглядеть следующим образом:
mysql> CHANGE MASTER TO MASTER_HOST='x.x.x.x',MASTER_USER='replication_user', MASTER_PASSWORD='password', MASTER_LOG_FILE='master-bin.0001', MASTER_LOG_POS= 04;Запуск репликации в неправильном месте может иметь катастрофические последствия: данные могут быть записаны дважды или не обновлены. Это приводит к дрейфу данных между мастером и слейвом.
Также при переключении мастера на слейв требуется найти правильную позицию и сменить мастера на соответствующий хост. MySQL не сохраняет бинарные логи и позиции от своего мастера, а создает свои собственные. При повторном согласовании слейва с новым мастером это может стать серьезной проблемой: точная позиция мастера при аварийном переключении должна быть найдена на новом мастере, после чего все слейвы могут быть повторно согласованы.

Для решения этой проблемы в Oracle и MariaDB был внедрен глобальный идентификатор транзакций (GTID). GTID позволяет автоматически согласовывать слейвы, и как в MySQL, так и в MariaDB сервер сам определяет правильное положение. Однако в обоих случаях GTID реализован по-разному, и поэтому они несовместимы. Если вам нужно обеспечить репликацию с одного сервера на другой, то она должна быть настроена с традиционным позиционированием бинарного лога. Кроме того, программное обеспечение для преодоления отказов должно быть предупреждено о том, что не следует использовать GTID.
Заключение
Мы надеемся, что дали достаточно советов, которые помогут вам избежать неприятностей. Все это — обычная практика экспертов по MySQL. Они прошли тяжелый путь обучения, и с помощью этих советов мы гарантируем, что вам не придется сталкиваться с таким опытом.
У нас есть несколько дополнительных статей, которые могут быть полезны, если захотите прочитать больше о репликации MySQL.
➕
 Руководство по MySQL
544 страницы · 2016 · 4.78 MB · русский
by Тахагхогхи С. & Вильямс Хью Е.
Руководство по MySQL
544 страницы · 2016 · 4.78 MB · русский
by Тахагхогхи С. & Вильямс Хью Е. MySQL по максимуму
866 страниц · 2018 · 102.51 MB · русский
by Бэрон Шварц & Петр Зайцев & Вадим Ткаченко
MySQL по максимуму
866 страниц · 2018 · 102.51 MB · русский
by Бэрон Шварц & Петр Зайцев & Вадим Ткаченко
