


Автор: Triple (http://webmasters.ru/forum/member.php?u=15783). Семантическое ядро – список ключевых запросов, которые будут давать трафик. Делю сбор семантики на несколько частей.
Подготовка
Ваша задача – полностью изучить тематику. Потратите ли вы на этого день или более – не важно. Здесь не стоит экономить. Делаете семантику по какой-либо болезни? Изучите как минимум десяток статей. Вы должны стать профи по этой болезни. Знать все детали, от диагностики до полного излечения.
В коммерческой тематике – знать свою аудиторию, какой тип ключей будет привлекать клиентов, какие ключи будет рациональнее использовать.
После завершения первого этапа – составляете структуру. Тут вам и потребуются знания, приобретенные на прошлом этапе. По медицинской тематике – ищете все разновидности болезни, способы расширения тематики. (простуда – ангина – грипп – кашель и т.д). По другим тематикам – аналогично.
2. Парсинг
Задача на данном этапе – собрать максимально большее количество ключей со всех возможных источников. Больше ключей до чистки, больше вкусных трафиковых после.
Вордстат. Им пользуются все – но не все пользуются им правильно. Плюс – это лишь вспомогательный инструмент, который, к примеру, вместе с википедией может помочь составить структуру сайта.
Да, он не выдаст полный список ключей, для этого мы используем другие источники. В соседней статье писалось – не стоит обращать внимания на НЧ ключи? Серьезно?
Для молодого сайта (я предполагаю, что СЯ собирается впервые и для нового проекта) – НЧ ключи это основа. Это база. Именно на них мы наращиваем траст и далее по методу матрешки переходим на СЧ и ВЧ. Иногда вообще не переходим, потому что они могут давать до 90% трафика.
Нажмите на изображение для увеличения.
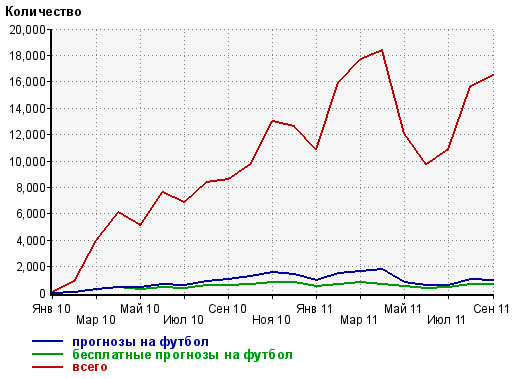
Картинка с блога Люстика
Рентабельность? Да, не стоит тратить по 10 usd на каждый НЧ ключ. Мы лишь добавляем эти ключи в статьи, заточенные под ВЧ\СЧ и получаем дополнительный трафик. Используем ту же простую математику. В статью объемом 10к символов (10 usd по больнице) можно легко добавить 10 НЧ ключей. Необязательно добавлять весь ключ целиком, достаточно добавить слово, которого не было в предыдущих ключах:
Если мы употребили “как построить дом” (так, условно), добавив слово “быстро” в статью и написав об этом пару предложений, статья уже ранжируется по ключу “как построить дом быстро”. Понимаете, о чем речь?
10 дополнительных НЧ ключей с частотностью 20 в 100 статьях могут принести дополнительно 600 и более уников трафика в день. Опять же, 600 уников трафика могут конвертироваться по разному. Они могут принести и 1000$ и 30$, зависит от тематики.
Теперь вы скажите, что я не учитываю кликабельность серпа и кучу других факторов. Нет. На практике вы получите больше в 1.5-2 раза. Палю информацию, которой не было ни в одном мануале по СЯ. Половина и даже более запросов в поиск – уникальные. Низкочастотники и запросы-единички. Они занимают почти половину запросов в поисковики. Остальную часть (50%) делят ВЧ и СЧ. Т.е на СЧ и ВЧ приходится грубо говоря по 25%.
Пруфлинк? Цитирую:
Основной поток запросов к Яндексу — уникальные, то есть такие запросы, которые в течение дня задали только один раз. В городах, где пользователей много, доля уникальных запросов обычно ниже — чем больше людей, тем скорее кто-то задаст запрос, который в этот день уже задавали. Например, в Хабаровске доля уникальных запросов — 60%, а в Москве — всего 43%.
https://yandex.ru/company/researches/2010/ya_regions_search_2010/
Запросы-единички: микронч, либо с очень маленькой (1-10), либо с вообще отсутствием (0) частотностей по вордстату.
Задание для владельцев ключевых баз (moab\etc): сравните общую точную "!" частотность популярных запросов и общее количество запросов единичек.
Задание для владельцев молодых посещаемых сайтов: сравните количество трафика с популярных запросов и количество запросов, с которых пользователи пришли лишь пару раз.
Уникальные запросы – видоизмененные запросы нашей семантики, суть которых – не меняется, а значит ответ на вопрос они давать будут. Соответственно, трафик приносить тоже.
Чем больше нч запросов мы употребляем в статье, тем больше посетителей будут идти на сайт с видоизмененных микроНЧ запросов. Надеюсь, вы поняли весь смысл. Используя 10 нч, расширяем количество ответов, которые дает статья и мы формально ранжируемся по 1000 запросов-единичек.
Я не говорю, что НЧ – это святой грааль. Я говорю, что их можно и нужно использовать. Фактически мы лишь вписываем их в итак большую статью, заточенную под СЧ и получаем бесплатный поисковый трафик.
Не говоря уже о других плюсах НЧ, такие как продвижение основного ключа (СЧ), обилие запросов, соответственно и относительно маленькая конкуренция – вкуснейший кусок для молодых сайтов, особенно коммерческих, где конкуренция огромная. Либо необязательно коммерческая. Есть ниши, где за один клик платят по 5-40$. Тогда каждая десятка посетителей будет золотом.
Далее я буду объяснять, где брать большое количество НЧ запросов и как работать с ними.
Прямой эфир. Вы можете поставить Колян на сервер, но это нерентабельно и займет долгое время. Я пользовался tools.promosite.ru. Нет, я не извлекаю НЧ из апдейтов ТИЦ.
Существует другой инструмент – http://tools.promosite.ru/last20keywords/
Поисковые подсказки. Тоже неплохой инструмент, только здесь нужно будет пользоваться прокси. И пробивать не только основной запрос (а-ля “гастрит”, но и использовать схожий алгоритм глубины парсинга вордстата. т.е, пробиваем и гастрит, и лечение гастрита и его симптомы. Получим намного большее количество ключей).
Базы ключевых слов. Пользуйтесь MOAB и Пастухова. На обе можно получить выборки за четыре и два бакса соответственно. Если нужны частые выборки, но нет денег – пользуйтесь fastkeywords.biz – четыре бакса за месяц анлимитных выборок.
Видимость mega index, spywords. Позже расскажу, как грамотно использовать. Пока что спарсите крупного конкурента.
Для двух вышеперечисленных инструментов создайте группу и сохраняйте все ключи там. Далее делайте выборки по запросу. Иначе вы получите большое количество нерелевантного мусора, которое вообще не подходит к вашему СЯ. Особенно с видимости.
Сбор расширений Sape, Semrush, Spywords. Последние два – дороговаты. Использовать по усмотрению. Либо попросите знакомого сделать выгрузку. Могут дать небольшой % вкусных ключей.
Счетчики статистики. Как вариант – попросить пароль у похожего по тематике сайта на бирже и спарсить кеи. По метрике – в основном все есть в моаб, новые данные аналогично просите у владельцев метрик.
3. Чистка
SHIFT и CTRL – две кнопки, которые в будущем упростят вам жизнь. Как пользоваться? Выделяете группы, нажимаете CTRL и к примеру, сбор частотностей. Сбор начнется по всем выделенным группам. То есть, вам не придется переключаться между каждыми группами и делать все заново.
CTRL + несколько выделенных групп + нажатие на задачу = задача начнет выполнятся для нескольких групп
SHIFT + задача = начнется выполнение для ВСЕХ групп.
Это к слову, если семантика у вас большая и нужно будет работать с несколькими группами. Многие до сих пор не знают эту комбинацию клавиш.
Задаете стоп слова и делаете удаление неявных дублей.Подходит абсолютно для всех задач. Далее пользуетесь фильтрами по своему усмотрению. Опять же используете shift и ctrl при нажатии на эту галочку:

Далее сбрасываете фильтры нажатием SHIFT и этой кнопки

Далее после автоматической чистки вы приступаете чистить все руками. Тут вам пригодятся знания из первого этапа подготовки. Я не могу дать точный алгоритм чистки, все зависит от ваших целей.
К примеру, вам нужны посетители в клинику.
Вы можете пойти двумя путями – привлекать много информационного трафика и с плохой конверсией преобразовывать посетителей в клиентов. Исключаем коммерческие ключи.
Можно воспользоваться коммерческими ключами и получать меньше, но с хорошей конверсией. Исключаем в данном случае информационные ключи.
Итак, короткий алгоритм чистки:
- Удаление ключей по стоп-словам
- Удаление неявных дублей
- Сбор данных – частотность, конкуренция, стоимость ключа и так далее
- Фильтры по собранным данным.
- Последний штрих, самый долгий – ручная чистка.
Конкуренция. Я выделю отдельную часть текста для этого типа данных. Принцип тот же, что и раньше – конкуренция равна количеству вхождений в title суммированной с количеством главных страниц в топ 10. НО.
Способ устарел и не является полностью актуальным, объясню почему.
Первый фактор. Если в выдаче есть 3 вхождения в заголовок, но сайты молодые – их будет обогнать легче, чем сайты с трастом. При этом KEI у нас будет одинаков в обоих случаях – 3.
Второй фактор. По ключу – “Как сделать ремонт в доме” конкуренция может быть 6 (формально), а по ключу “а как сделать ремонт в доме” – 0. При этом, реальная конкуренция будет 6, вовсе не 0. Пример конечно неудачный, но суть вы поняли. Одно лишнее слово, которое не меняет суть ключа – и разница в конкуренции может быть колоссальной.
Резюмирую.
KEI от 1 до 3 – показывает наличие конкуренции
KEI от 4 до 10 – показывает наличие сильной конкуренции
KEI 0 – показывает, что возможно, конкуренции нет
Как же быть?
Было бы идеально, если бы авторы KK добавили автоматический анализ Топа – пузомерки, возраст конкурентов, размер их текстов, количество доноров по ahrefs, но они отказались это делать, т.к не рентабельно.
Я предполагаю, что примерно такой же алгоритм имеет мутаген. Значение мутагена до 6 – является признаком отсутствия явной конкуренции. Поэтому, если нам требуются только низкоконкурентные ключи – сначала отсеиваем все запросы, KEI которых не равен нулю, а затем отсеиваем ключи, конкуренция по мутагену которых больше 6.
Мутаген – удовольствие не из дешевых. Поэтому чекаем на конкурентность только запросы с KEI 0. Всё просто. KEI > 0 уже показывает наличие конкуренции. Нет смысла проверять заново конкуренцию по мутагену. В итоге мы получаем более правильные данные по конкуренции. Они не совершенны, но намного лучше и точнее.
4. Экспорт
Без группировки не обойтись. Либо используете стандартные функции кейколлектора, т.е анализ групп и дальнейший экспорт, либо специальный софт.
Я пользуюсь стаднартной функцией, во многих случаях группировал вручную после стандартной группировки, переодически пользовался топвизором, очень сильно понравилась задумка http://rghost.ru/7mdYQqq7l (demo). Полную версию искать придется самим, т.к нельзя рекламировать ссылки на другие форумы.
Хитрости, фишки, наработки
100% низкоконкурентные ключи и быстрый анализ конкурентов.
В кейколлекторе есть хорошая функция – экспортировать данные о поисковой выдаче. Она работает, когда собраны KEI. Делаем экспорт. Парой кликов мы получаем очень полезную информацию, а именно – всех конкурентов из топ 10 по каждому запросу нашего семантического ядра.
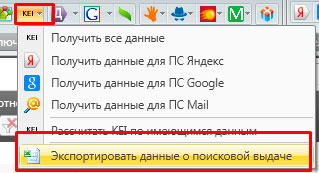
Итак, делаем в экселе сортировку от А до Я и вбиваем домены конкурентов в NetPeakChecker. Анализируем возраст каждого домена. Оставляем только домены с возрастом до 6 месяцев. Если таких не будет – постепенно увеличиваем фильтр до года.
Затем анализируем беки с помощью ahrefs. Оставляем только тех, у кого беков меньше всего. Количество – по усмотрению (в разных случаях могут быть разное количество конкурентов).
Парсим с этих сайтов ключи с помощью видимости megaindex и spywords. Чекаем позиции этих сайтов по этим ключам в том же кейколлекторе.
Оставляем только те запросы, по которым молодые сайты в топ 4. На выходе получаем списки запросов, по которым легко обогнать конкурента. Осталось лишь написать статью лучше, да и на пару беков больше.
Автоматический отсев нерелевантных по гео запросов
Если вы собираете ключи исключительно под, к примеру, Москву, то сделайте настройку директа под регион – Москва. В итоге все запросы, которые не подходят под этот город, будут иметь частотность 0. Исключать их вручную больше не потребуются. Они будут иметь нулевую частотность и вы их автоматически удалите как пустышку.
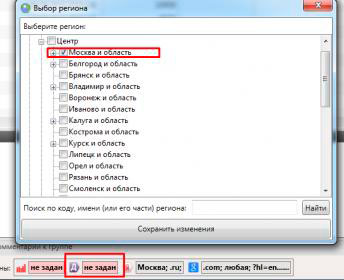
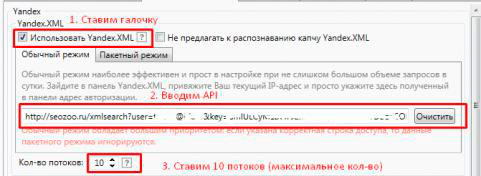
Быстрый сбор KEI
Конкуренцию можно собирать с помощью API. Она стоит дешево – собирает быстро. Регистрируемся на seozoo.ru, пополняем баланс и вытягиваем здесь http://seozoo.ru/apidocs#xml ключ api. Скорость парсинга выдачи увеличится в 6-10 раз.


Сбор семантики под буржнет.
Это дело можно так же провести в кейколлекторе. Процесс идентичен. Все регионы ставим на ориентируемую страну. Нужны только бурж-аналоги инструментов.
- Вордстат меняем на google adwords
- Директ меняем на google adwords
- Базы Пастухова и moab на англоязычные базы того же Пастухова и amazing keywords ENG
- Парсим поисковые подсказки
- С помощью прокси парсим KEI по гуглу.
- С помощью semrush и spywords парсим ключи конкурентов.
Повторный ввод запросов
Чтобы повторно не вводить данные и в поисковые подсказки, можно воспользоваться функцией – копировать с wordstat. Списки запросов одновременно скопируются с заданных запросов для парсинга в вордстат.
Основные выводы и принципы, которые вы узнали после прочтения статьи.
- Большое количество трафика идет на сайт не только с ВЧ и СЧ. НЧ имеют солидную долю трафика. Это стоит учитывать.
- Большое количество трафика – идет с микроНЧ и абсолютно уникальных запросов, которые ранее не искались в этом месяце.
- НЧ ключи помогают разнообразить статью и дать больше ответов на разные вопросы. В итоге сайт ранжируется по тысячам ключей-единичек
- Большие статьи – лучший выбор. И по рентабельности и по полученному профиту.
- Чтобы использовать НЧ, достаточно вписать слово, которое ранее не употреблялось в предыдущих ключах
- KEI 0 уже не показывает отсутствие конкуренции, как таковой. Данное значение показывает возможность ее отсутствия.
- Использования мутагена помогает улучшить данные о конкуренции и сделать их более правильными в целом.
- Экономить на мутагене можно, проверяя конкуренцию только у запросов с KEI 0. KEI, отличный от нуля уже показывает наличие конкуренции.
- Функция – экспорт поисковой выдачи может предоставить вам всех конкурентов за пару кликов.
- Весь функционал кейколлектора находит своё применение при сборе семантического ядра.



Дмитрий#
Очень полезный и интересный материал. Сейчас расширяю СЯ буду использовать Вашу методику.
coder hol es /* Админ */#
Спасибо Вам за пост, методика принадлежит автору)