


Автор: Михаил Жуковец, SEO-специалист агрегатора Price.ru
Не будем вспоминать в очередной раз «что такое кластеризация» и «для чего она нужна». На эти вопросы давным-давно дали ответы различные сервисы, предлагающие услуги по кластеризации поисковых запросов на основании SERP. Ниже мы разберем, как провести эту нехитрую процедуру самостоятельно и бесплатно, или с символическими затратами.
Для начала надо установить и настроить python, но, поскольку желающих с этим возиться немного, то рекомендую сразу обратиться к сборке Anaconda, которая позволяет быстро установить сам python и все необходимые библиотеки.
Ниже по тексту будут приведены сниппеты для python 3.
Векторное представление ключевых слов
Чтобы сделать наши ключевые слова удобными для обработки, необходимо провести их векторизацию. Звучит пугающе, но на самом деле все очень просто – все ключевые фразы разбиваются на уникальные слова и кодируются. По сути они преобразуются в большой список и дальше вместо каждого ключевого слова мы размещаем длинную строчку цифр, соответствющую нашему списку всех уникальных слов. Если слово есть в фразе – то ставим 1, если нет , то 0. Получается что-то вроде такой таблицы.

Чтобы не придумывать велосипед, удобно воспользоваться готовыми библиотеками. Такую матрицу можно получить при помощи класса CountVectorizer из библиотеки scikit-learn.
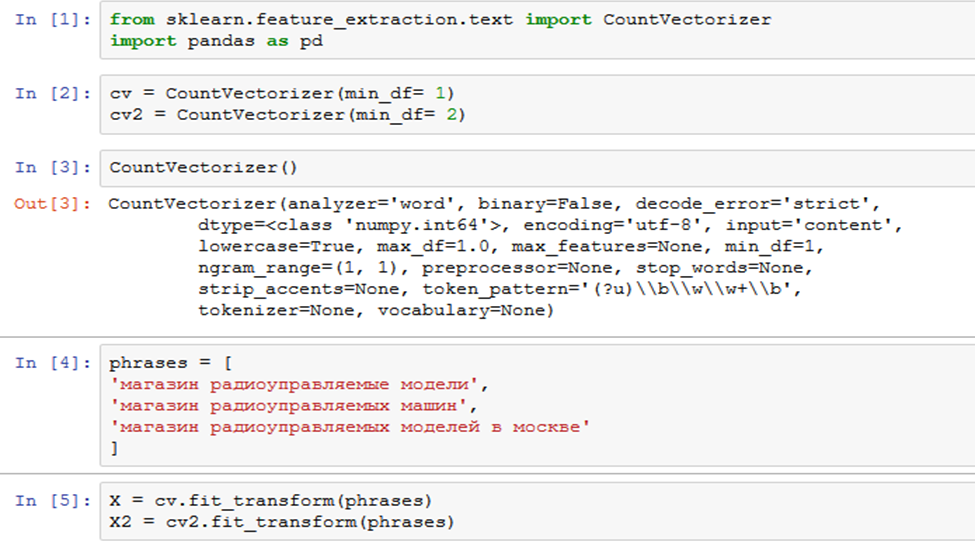
Здесь мы создаем два разных векторизатора, которые отличаются лишь одним параметром – минимальной частотой слова. Для векторизатора cv минимальная частота слова, которое он учитывает равна единице, а для cv2 двойке, то есть все слова с частотой меньше двух – не учитываются при построении вектора. Если слово встречается только один раз во всех ключевых фразах – то нет смысла занимать оперативную память подобной информацией. Мы не сможем найти какие либо подходящие пересечения по слову, у которого нигде нет пары.
Результатом обработки списка phrases, на котором мы будем разбирать примеры векторизации видно, как поменялись итоговые таблицы для сравнений.
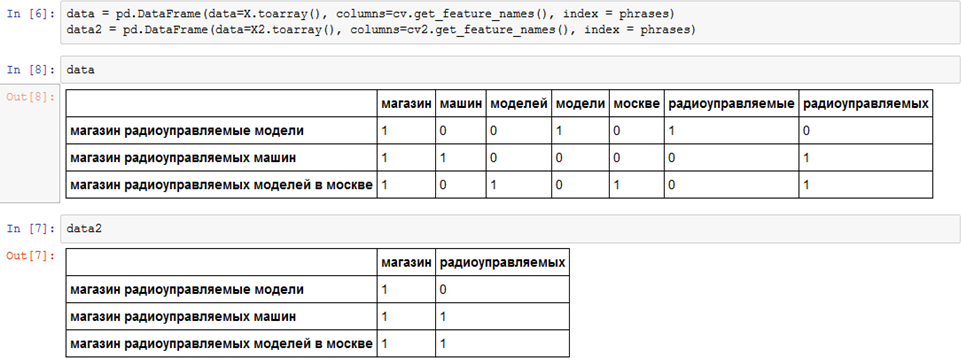
Слова, которые использовались лишь единожды, были отброшены, и наши многословные ключевые фразы превратились в двухсловники.
Внимательный читатель, конечно, заметил, что многие значимые слова были порезаны настройками векторизатора, и имели смысловую пару, но бездушная машина сама по себе не способна увидеть что «моделей» и «модели» это просто разные склонения одного и того же слова. Для того, чтобы устранить подобные ошибки мы предварительно проведем процедуру, которая называется лемматизация – приведение словоформы в её нормальную форму.

Таким несложным способом мы можем трансформировать все наши ключевые фразы в нормализованный вид и переучить векторизаторы.

В итоге мы получаем следующие матрицы

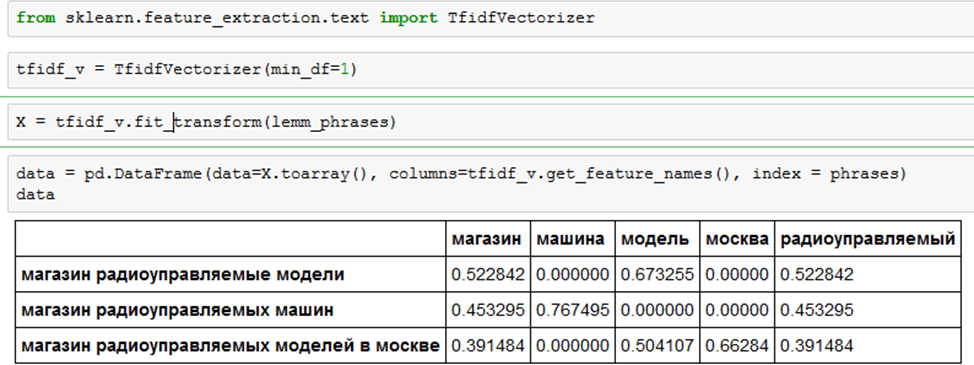
Теперь, после применения второго векторизатора, нам удалось сохранить намного больше полезной информации. Он хорошо видит слово «модель» и различные формы «радиоуправляемого».
Поскольку все SEO-специалисты не понаслышке знают, что количество слов редко переходит в качество вместо CountVectroizer лучше использовать TfidfVectorizer. Он очень похож на предыдущий векторизатор, но вместо числа 1 или 0 проставляет значимость каждого слова рассчитывая её по Tf-Idf.
Используется он точно так же как и обычный CountVectorizer, но возвращает другие результаты.
Ну и вишенкой на торте совместим лемматизатор и TfidfVectorizer в один класс, который позволит проводить преобразование на лету. Вообще, для задач кластеризации в этом нет необходимости, но такой код, на мой взгляд, выглядит более удобным и читаемым. Использовать его или нет – личное дело каждого.

Настройка векторизаторов
У всех разобранных векторизаторов есть несколько общих настроек, которые могут пригодиться:
• stop-words – список слов, которые не будут учитываться при векторизации;
• token_pattern – регулярное выражение, по которому строка разбивается на токены. Обычно это просто разделение на слова, но могут быть выделены и другие сущности;
• max_df – токены имеющие частотность выше этого значения не будут учитываться. Можно указать процент через коэффициент – 0.9 будет обозначать что 10% наиболее частых слов будут отброшены;
• min_df – токены имеющие частотность ниже этого значения не будут учитываться. Можно указать процент через коэффициент – 0.1 будет обозначать что 10% наиболее редких слов будут отброшены.
Полный список всех параметров можно посмотреть тут.
Кластеризация по составу фраз алгоритмом K-Means
Вот мы, наконец, и добрались до кластеризации, ради которой все это и затевалось. В данном примере мы рассмотрим кластеризацию по составу фраз, которая позволит выделить те словосочетания, которые между собой сильно связаны и имеют большое количество пересечений значимых слов.
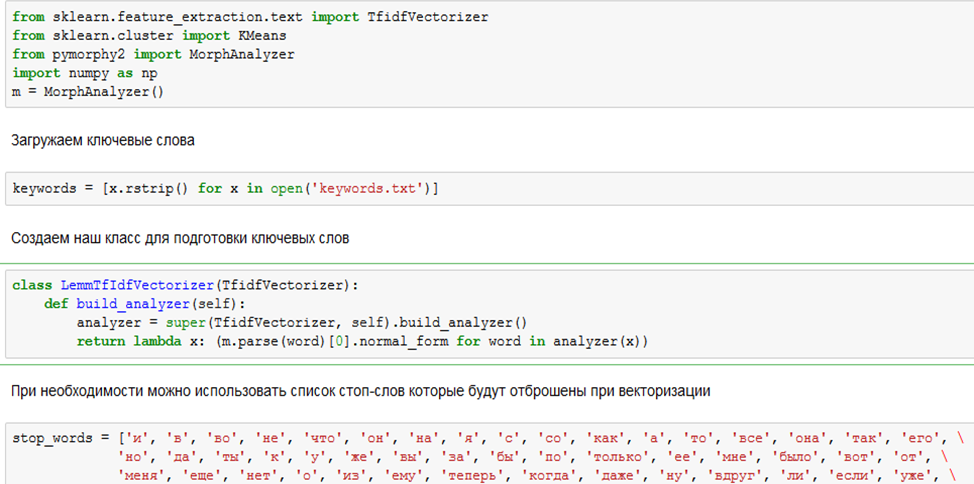
Для дальнейшей работы нам пригодится класс KMeans из библиотеки scikit-learn. Ниже скриншот подготовительной части, где мы подгружаем ключевые слова из внешнего текстового файла, создаем класс для векторизации и заполняем список стоп-слов, если он у вас есть.
Для настройки алгоритма KMeans удобно использовать следующие параметры:
• n_clusters – количество кластеров, на которые будут делиться данные. Минусом данного алгоритма является необходимость изначально указать, на какое количество групп будут поделены слова.
• max_iter – максимальное количество итераций. Работа будет принудительно остановлена при достижении этого числа. Иногда алгоритм «залипает» на некоторых видах данных, и указывается конкретное статичное число, которое позволяет избежать бесконечной работы.
• n_init – сколько раз будет инициализироваться алгоритм с различными начальными центроидами. Чем больше инициализаций – тем лучше кластера описывают реальную структуру данных и тем дольше работает алгоритм.
• tol – доверительный предел, при достижении которого кластеризация будет остановлена.
• n_jobs – количество параллельных потоков работы алгоритма
• random_state – параметр позволяющий добиться воспроизводимости одних и тех же результатов при разных запусках алгоритма
Сама кластеризация много места не занимает.
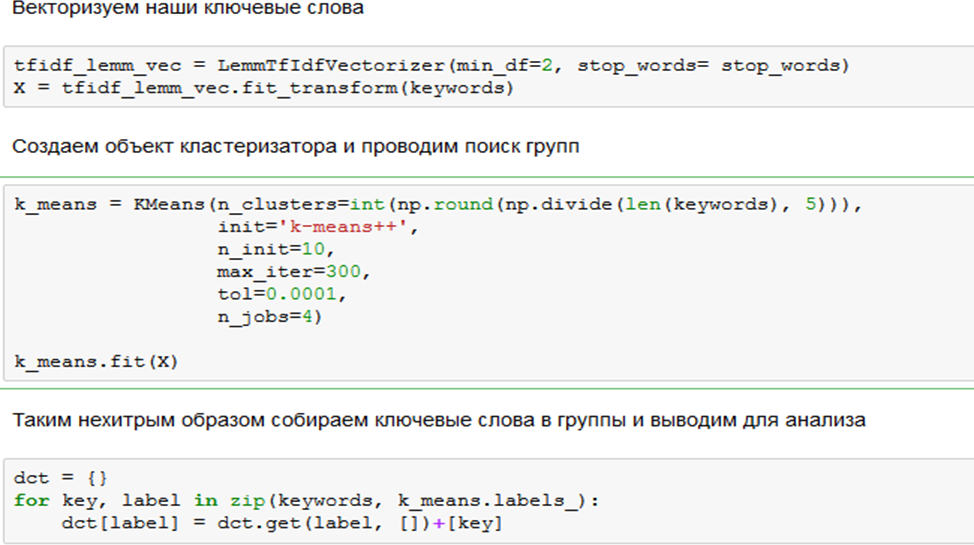
Так можно посмотреть, что у нас там получилось, и при помощи последнего сниппета сохранить результаты в csv
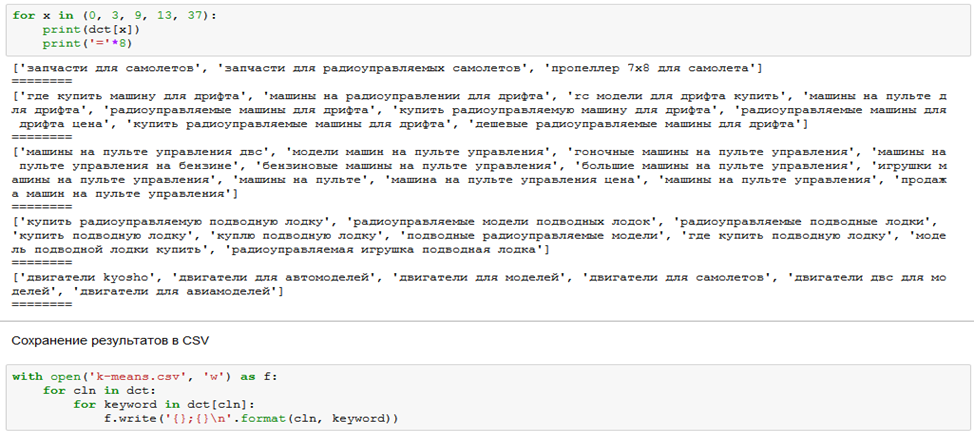
Иерархическая кластеризация по SERP Яндекса
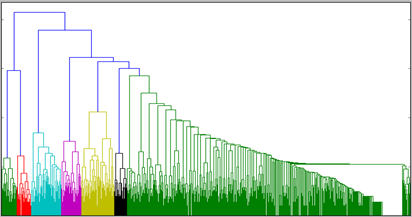
Иерархические алгоритмы строят не одно разбиение выборки на непересекающиеся кластеры, а систему вложенных разбиений. На выходе мы получаем дерево кластеров, корнем которого является вся выборка, а листьями – наиболее мелкие кластера.
Для начала нам нужно собрать ТОП из какой либо поисковой системы. Для примера был выбран топ Яндекса, т.к. с ним удобно работать через XML. По глубине – топ 10, хотя вменяемые результаты получаются и на топ 20-30, но вот дальше начинается ерунда в группировке. После того, как мы собрали серпы у нас получаются следующие конструкции:
• keywords – список в котором лежат наши ключевые слова
• serps – список в котором лежат на соответствующих ключам строках серпы, в которых все урлы серпа просто разделены между собой пробелом.
Вот тут нам как раз и пригодится возможность указывать собственное регулярное выражение для разбиения фразы на специфические токены. Для нас каждым уникальным токеном будет какой либо уникальный url.
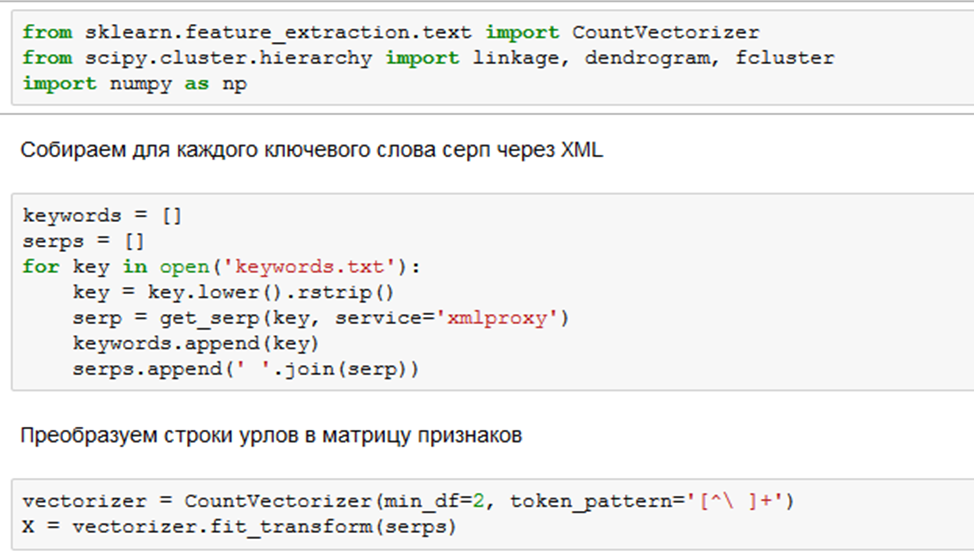
Ну и аналогично предыдущему примеру производим кластеризацию:
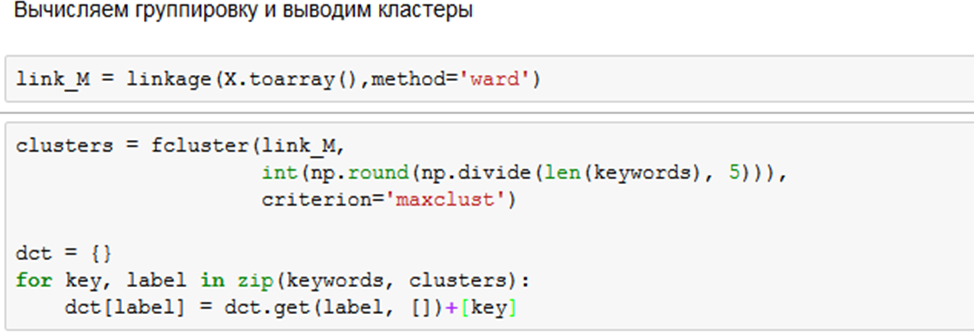
У функций linkage и fcluster достаточно много различных настроек, но, думаю, они больше будут интересны исследователям и специалистам, так что ограничусь лишь ссылкой, где можно найти все необходимые описания.
Использование данного алгоритма так же позволяет получить адекватные результаты группировки

Ну и при желании можно визуализировать дерево, которое получилось в процессе кластеризации

*Источник: email рассылка Searchengines.ru



Дмитрий#
Добрый день, можно ли получить файл keywords.txt для примера? Заранее большое спасибо
coder hol es /* Админ */#
Здравствуйте! К сожалению, доработка и дополнительные материалы по запросу не предусмотрены – вся информация, как правило, содержится в материале и ссылках к нему, если таковые имеются.
Игорь#
Добрый день! А есть в сети готовые реализации?
coder hol es /* Админ */#
Здравствуйте! Собственно – попробуйте программы keyaccort и Majento "Кластеризатор".