


Автор: Александр Селиванов, руководитель разработки сервисов офлайн-измерений Яндекса
Ежедневно пользователи Яндекса задают поиску более 250 млн запросов и получают на них ответы. Задача оценки качества поиска заключается в том, чтобы понять, решил пользователь свою задачу или нет, задав поисковый запрос.
Почему важно оценивать качество?
Оценивать качество поиска очень важно, так как нужно понимать, приносит ли поиск пользу тем людям, которые им пользуются. При этом нужно понимать, что мир постоянно меняется, пользователи узнают новые слова и понятия и тоже меняются, поиск со временем меняется, потому что выкатывается одна версия за другой, и нужно понимать, куда движется весь механизм.
Почему важно ОЦЕНИВАТЬ качество?
Важно давать численную оценку происходящему, так как изменения бывают разными. Для того, чтобы измерить пользу от одного конкретного изменения, нужно численно представлять, что изменения А дают такой-то профит, а изменения Б – такой же или меньший. Это нужно для однозначной приемки тех изменений, которые делаются.
Почему ВАЖНО оценивать качество?
Постоянное внесение изменений необходимо потому, что порог перехода в другую поисковую систему очень низкий. Для этого пользователю достаточно всего лишь открыть другую вкладку, задать другой ПС свой запрос и решать свои задачи там. Если у пользователя вдруг неожиданно лег Facebook или ВКонтакте, вряд ли он побежит срочно пользоваться Snapchat’ом, так как там нет его друзей и нет его сети контактов. А если лежит поиск Яндекса, то пользователь очень просто идет в другую поисковую систему и прекрасно себя чувствует. При этом, если поиск не решает ту задачу, которая есть у пользователя, то он также переходит в другую поисковую систему. А это значит, что отвечать бесполезно и не отвечать вообще – означает одно и то же, только детектировать такие случаи гораздо сложнее.
Как измеряют качество?
1. Маркетинговые опросы. Это самое простое, что можно сделать.
2. Онлайн-эксперименты. Одним из наиболее популярных способов провести онлайн-эксперимент является A/B-тестирование. Когда выкатывается одна из версий поиска на группу А (довольно большую), другая версия – на группу Б, и отслеживается, как пользователи себя ведут в поведенческой модели в этих двух версиях. Такой метод позволяет непосредственно работать с пользователем и получать от него обратные сигналы. Однако такая модель, с одной стороны, является достаточно сложной для измерений, а с другой – группе Б может так не понравиться показанная версия поиска, что они просто перейдут в другую поисковую систему.
3. Оценка офлайн-модели. Здесь аналитики не имеют дела с настоящим пользователем, они его модулируют. Моделируются также его действия, совершаемые на поиске, прогнозируется его удовлетворенность результатами.
Офлайн-модель позволяет достаточно быстро проводить эксперименты, в том числе и очень «опасные», которые нельзя выкатывать в онлайн, никак не ограничивая эти эксперименты ни во времени, ни в количестве.
Как считаются метрики
Метрика удовлетворения пользователя поисковым ответом – называется метрикой «счастья пользователя». Это довольно сложное понятие, куда может входить и быстрый ответ прямо на странице выдачи, и демонстрация только доверенных ресурсов, и учет многозначности запроса (вариативность выдачи), и региональность, а иногда даже реклама. Все это множество сигналов можно измерять по отдельности, но конечная метрика счастья зависит от их совокупности.
Пример из поиска по картинкам. Здесь представлены два поисковых ответа по запросу [яндекс бенуа]. Допустим, что такая метрика, как цветность картинки, имеет прямое отношение к счастью пользователя:
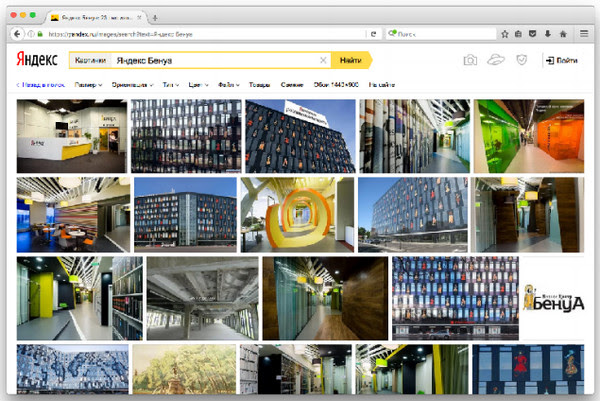
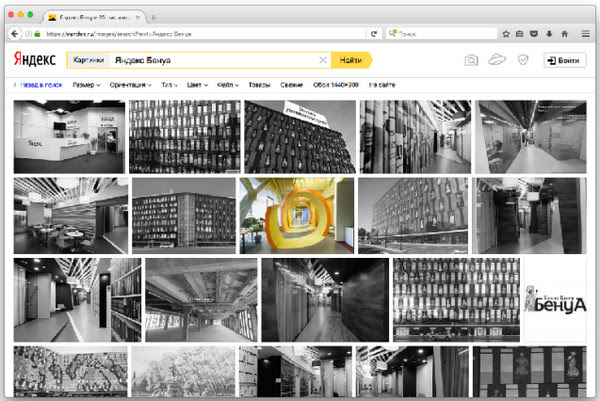
Задав этот запрос в картиночный поиск, можно начинать парсить данную поисковую выдачу. Здесь вводится понятие searchengine response page – это поисковый ответ. У этого поискового ответа могут быть запросы, регион пользователя и количество документов. Далее уже начинается парсинг всех картинок, которые мы представляем в виде компонентов, имеющих свой url, текстовое описание, размер. Для того, чтобы посчитать цветность, нужны сигналы о том, какая картинка цветная, какая нет. Этот сигнал можно получить с помощью ручной разметки, либо какой-то программы, либо с помощью машинного обучения.
Важно следующее – это сигнал имеет какую-то ключевую особенность. Обычно это картинка, представленная в виде url, и этот сигнал можно подклеить на этот url. Поэтому берется поисковая выдача, из нее вычленяются url картинок, на них наклеивается сигнал о том, какая картинка цветная, а какая нет, и таким образом уже можно посчитать долю цветных картинок в данной поисковой выдаче (ImagesColor). В первом случае эта метрика равна 0,91, во втором – 0,12.
Но предположим, что наши пользователи, при прочих равных, любят картинки с большим разрешением. Посчитали метрику среднего разрешения в поисковой выдаче (ImagesSize), которая в первом случае составила 0,52, а во втором – 0,55.
Далее важно все-таки построить эту абстрактную «метрику счастья». С помощью элементарного полинома, значения обеих метрик складываются, тем самым уже давая возможность численно понять, какая система лучше, по этому конкретному запросу.
F (Color + Size) = α*IC + β*IS
На самом деле улучшить поиск и даже сделать его идеальным по одному запросу – достаточно просто. Гораздо сложнее сделать таковым поиск для всех пользователей и по всем запросам. Поэтому, для того, чтобы добавить в приведенный выше пример больше статистики, нужно задать целую группу запросов и, соответственно, начинать измерения на этом большом количестве результатов. Вот конкретно здесь и начинают работать все статистические критерии, которые можно в этом месте применять:
F [queries] = α*IC[..] + β*IS[..]
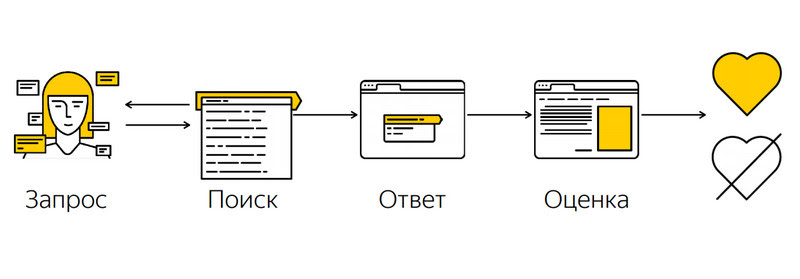
В итоге процесс модулирования действий пользователя выглядит так:
После этого результаты (отчет о том, какая версия ПС лучше) уже можно показать менеджеру проекта или аналитику поиска.
Инструменты оценки качества
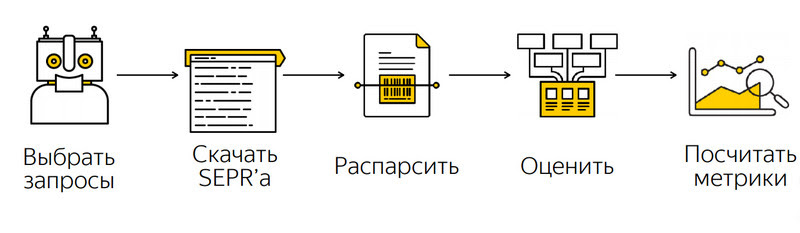
Для сбора контрольной выборки запросов используется Log miner, задачей которого является собрать как можно большую выборку запросов и научиться ее обновлять. Для того, чтобы данные были свободны от смещений в сторону тех или иных временных явлений, отражающихся на поиске (праздники, выходные, Новый год), берется как можно большее количество пользовательских логов за довольно таки продолжительное время.
Следующий инструмент – это Scraper. Он работает с двумя системами – контрольной (текущая версия ПС) и бетой (версия ПС с какими-либо изменениями, качество которых нужно оценить). Задача инструмента заключается в том, чтобы одновременно прокачать эти две системы и получить поисковые ответы по ним.
Следующая система – это Assessment, система получения сигналов. Исторически так сложилось, что первые сигналы Яндекс получал с помощью ручной разметки, с помощью асессоров, задача этого инструмента заключается в том, чтобы следить за качеством асессорских сигналов.
Связующим инструментом является Metrics, который агрегирует все асессорские оценки качества, отдает запросы в Scraper, получает сигналы, вычисляет метрики и предоставляет пользователям интерфейс для работы и для детального анализа того, что происходит в обоих версиях ПС.
Такая система, именно в этой архитектуре, существовала очень долго. Задачей разработчика было добавление новых сигналов и новых расчетов метрик. Со временем возникала необходимость в добавлении все новых и новых сигналов, поэтому систему пришлось расширить и добавить в нее еще несколько сервисов:
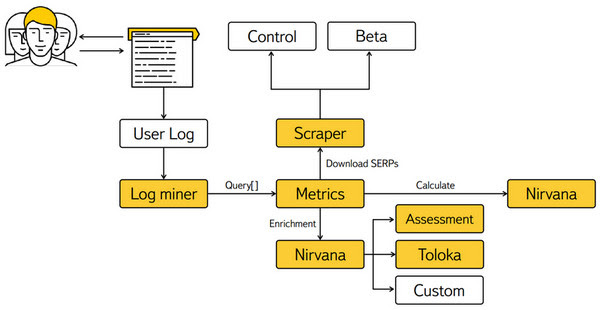
Сервис Nirvana позволяет аналитикам создавать свои бизнес-процессы по получению новых сигналов, вкладывать туда свою кастомную логику, например, могут использовать тот же Assessment или свои инструменты для машинного обучения, а могут использовать недавно появившийся сервис Toloka.
Вся эта архитектурная система работает на микросервисах, в основном используется язык java, реляционные базы данных и SQL. Система используется в нескольких сценариях:
• Приемка новых изменений
• Анализ исторических данных
• Мониторинг
Данная система используется для всех сервисов Яндекса, которые имеют контент: веб-поиск, мобильный поиск, картинки, видео, геопоиск, Маркет. Работает с big data, потому что приходится сравнивать различные элементы поискового ответа, добавлять сотни сигналов, добавлять сотни метрик и производить десятки тысяч вычислений в день. Развитие этой системы стремится к тому, чтобы создать одну большую офлайн-платформу для проведения экспериментов, чтобы разработчики и аналитики поиска могли удобно добавлять свои сигналы, создавать свои метрики и принимать те или иные изменения в поиске. И чтобы настоящие, несмодулированные пользователи поиска могли видеть только лучшие из этих изменений.
*Источник: email рассылка Searchengines.ru



Дмитрий Мотовилов#
Спасибо. Очень позновательная статья
coder hol es /* Админ */#
)Пожалуйста